
Research
A report on the research funded by Imminent’s Grant for the introduction of parallel decoding for speeding up translation models and language models.
Introduction – The issue at hand
In a world increasingly reliant on digital communication, the ability to break language barriers efficiently is more crucial than ever. Machine Translation (MT), a sub-field of Natural Language Processing, plays a pivotal role in this global exchange of information. While efforts have long been made to increase the quality of these systems, speed and efficiency have historically fallen by the wayside in favor of greater emphasis on the precision and accuracy of the translation. Previous efforts have attempted to increase the speed but they usually required a complete redesign of the machine translation system with drastically worsening quality. A team of researchers from GLADIA (Sapienza University) embarked on this research to tackle the efficiency bottleneck in MT while maintaining the exact high quality as standard systems.
Methodology
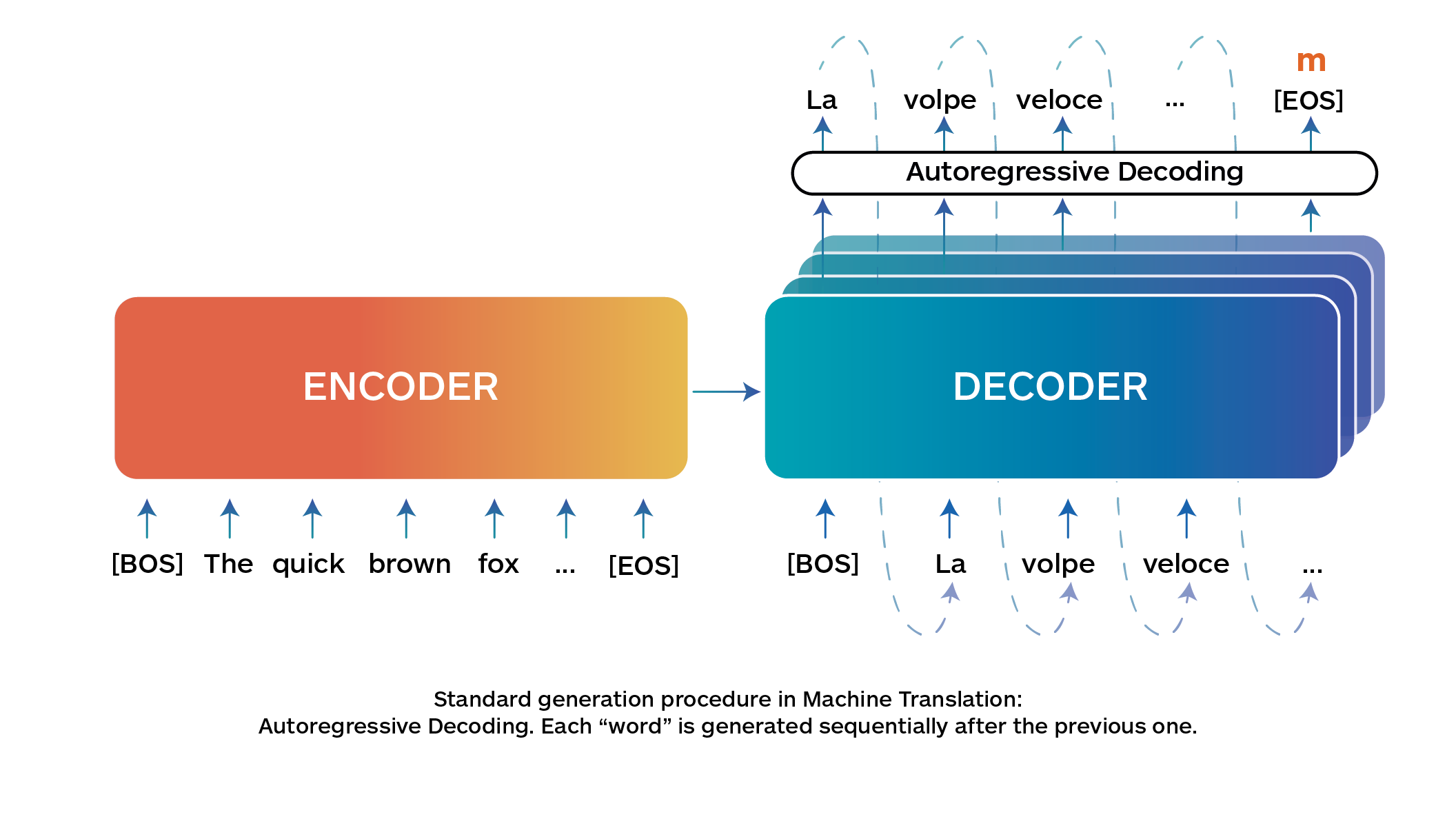
Currently, machine translation predominantly relies on au- toregressive decoding, which, while effective in maintaining translation quality, is slow due to its sequential processing. This autoregressive decoding procedure works by producing a translation from a one “word” (also referred to as a token) at a time model: the system generates the translation for the first word, then the second, and so on until it finishes the translation (Fig. 1).
A team of researchers at Sapienza proposed a novel procedure called Parallel Decoding that, instead of generating the translation sequentially, generates the translation for multi- ple tokens in parallel, speeding up the generation process while keeping the same quality of autoregressive decoding. Parallel Decoding works by generating the whole sentence or a block of b words in parallel. Starting from an initial draft translation (they used special [PAD] tokens), it gradually re-fines it for k iterative steps until the translation does not change anymore (Fig. 2).
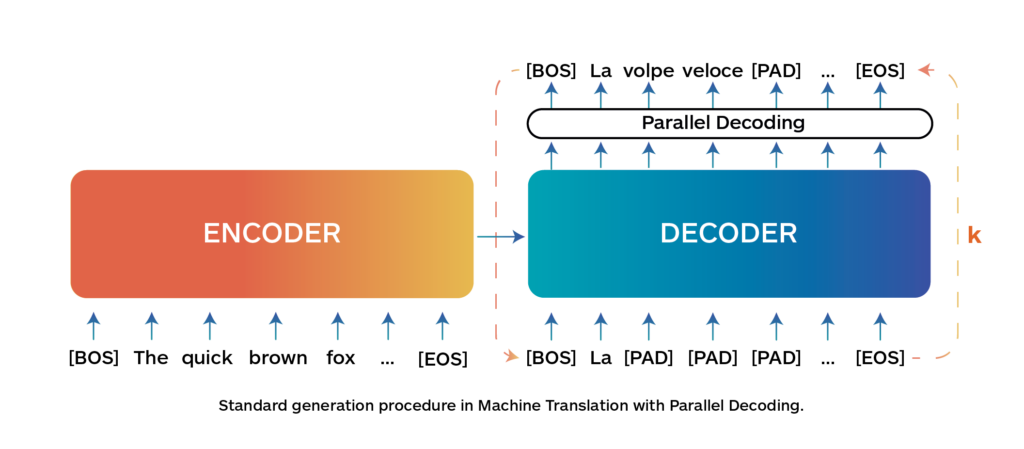
Their approach is based on a simple observation: decoding can be rephrased as a system of nonlinear equations with m variables and m equations. These equations can be solved by substitution (autoregressive decoding – slow and exact) or by using Jacobi or Gauss-Seidel fixed-point iteration methods (parallel decoding – fast and exact).
The team developed three innovative algorithms for Parallel Decoding:
- Jacobi Decoding (PJ): Iteratively translates the entire sentence in parallel.
- GS-Jacobi Decoding (PGJ): Splits sentences into smaller blocks, generating the translation in parallel within a block and autoregressively between blocks.
- Hybrid GS-Jacobi Decoding (HGJ): Similar to GS-Jacobi Decoding but with dynamic handling of the sentence length.
Crucially, the team showed that all the algorithms mathematically guarantee the same quality of standard autoregressive decoding while introducing a speedup.
Why This Research Matters
Compared with all the previous approaches, this was the first time that a method introduced a speedup without any modification to the model nor additional requirements, by just a drop-in replacement of the decoding algorithm. Results showed that indeed the method introduced a speedup up to 2x while maintaining the same quality of autoregressive decoding (Fig. 3).
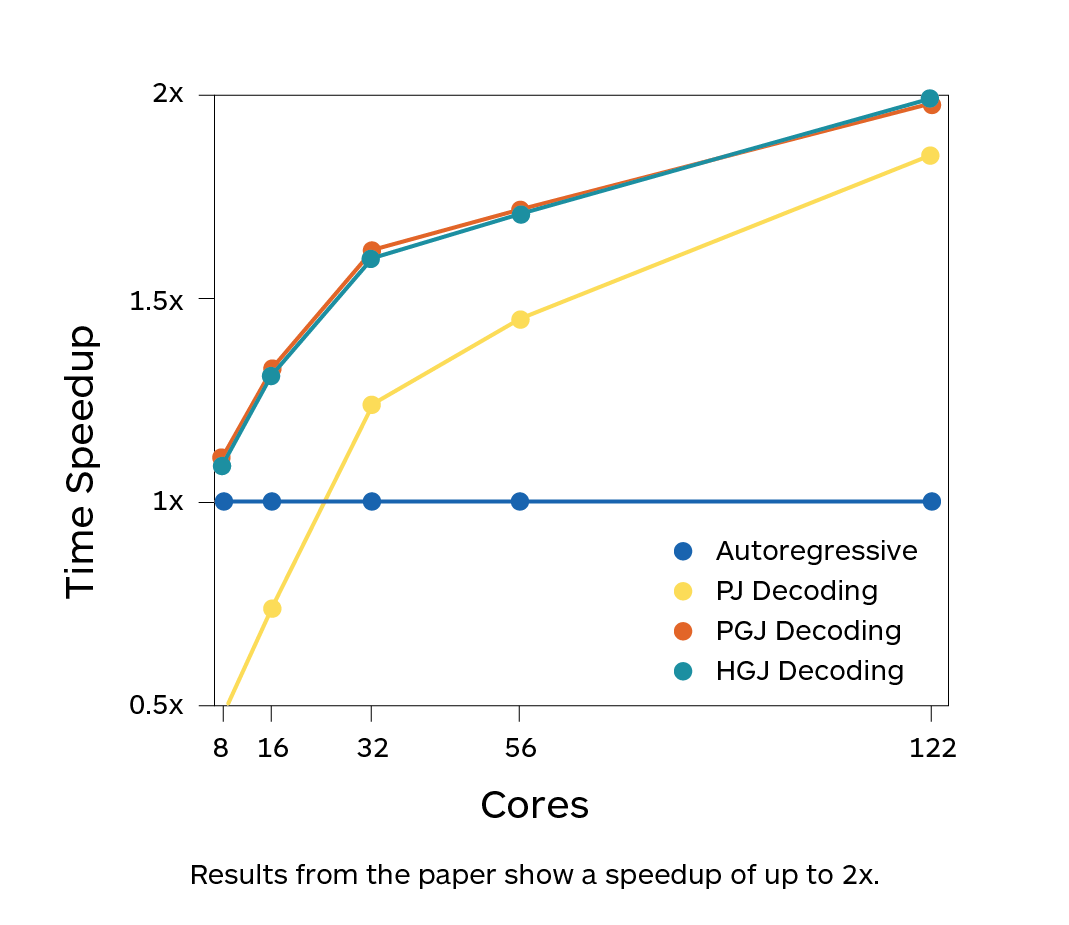
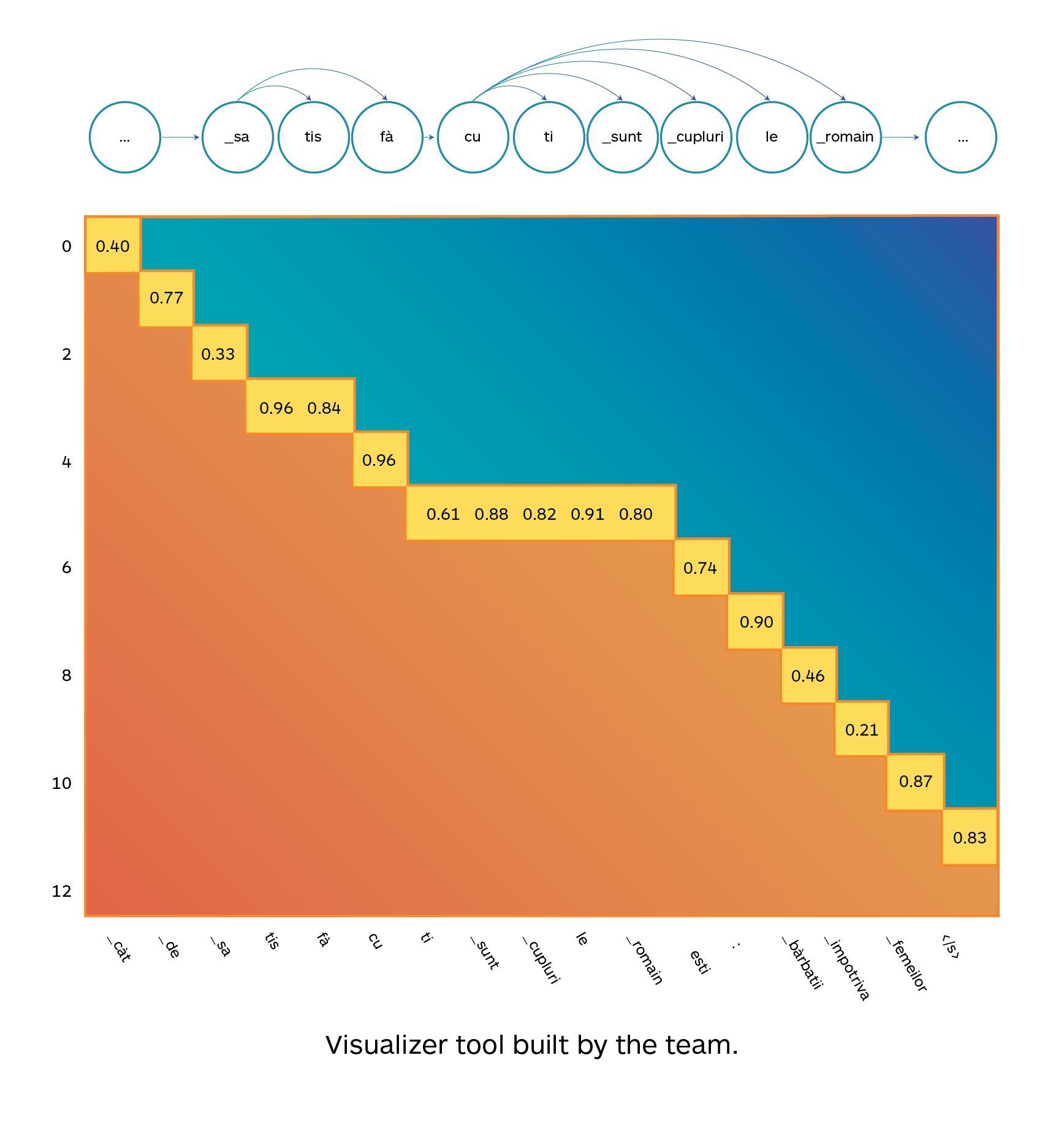
Furthermore, the authors also built a visualizer tool to inspect when the generation is performed in parallel and multiple tokens are decoded in parallel. The example on the right (Fig. 4) illustrates a translation from English to Romanian, using the sentence “How satisfied are the Romanian couples: men versus women”→”Cât de satisfacuti sunt cuplurile romanesti: bărbatii împotriva femeilor”. All the highlighted tokens are the steps decoded in parallel and show where the speedup is introduced.
Large Language Models with Parallel Decoding
Beyond machine translation, this approach is so widely adaptable that it can also be used in modern Large Language Models to speed up the generation process. In this direction, lmsys, the same company behind Vicuna, a famous language model, has already extended the Parallel Decoding approach to make it work with Meta LLaMA-2, showing speedups ranging from 1.5x to 2.3x and confirming the results obtained with Machine Translation. They dubbed their approach Lookahead Decoding and recently released a preprint with their findings. This confirms that Parallel Decoding is already having a huge impact on the world, shaping research directions and speeding up models used in production at the moment of writing.
Compared to other works (e.g., Speculative Decoding), approaches based on Parallel decoding eliminate the need for an additional draft model and offer the significant advantage of being compatible with any existing model without requiring modifications or additional prerequisites.
The team behind the breakthrough
This research was spearheaded by a team of computer scientists working at GLADIA, a University lab at Sapienza University focused on Artificial Intelligence and Machine Learning. The work was carried out after the team, led by Andrea Santilli, a Ph.D. student at the lab, won the prestigious Imminent Research Grant – Translated’s yearly award given to the best innovations in Machine Translation.
Specifically, the team won the award for the best proposal in the category “Machine Learning Algorithms For Translation,” chosen from 70 submissions by world renowned experts. Each member brought a unique set of skills and perspectives, crucial in addressing the complex challenges of speeding up the generation process while keeping the same quality of standard machine translation models.
Their combined expertise in NLP, algorithm development, and machine learning was instrumental in the success of this project.
Team Members:
Andrea Santilli, NLP Researcher
Silvio Severino, NLP Engineer
Emilian Postolache, Generative Models Specialist
Valentino Maiorca, Representation Learning Specialist
Michele Mancusi, Generative Models Researcher
Riccardo Marin, Co-supervisor of the project
Emanuele Rodolà, Supervisor and P.I. of the lab GLADIA

Imminent Research Grants
$100,000 to fund language technology innovators
Imminent was founded to help innovators who share the goal of making it easier for everyone living in our multilingual world to understand and be understood by all others. Each year, Imminent allocate $100,000 to fund five original research projects to explore the most advanced frontiers in the world of language services. Topics: Language economics – Linguistic data – Machine learning algorithms for translation – Human-computer interaction – The neuroscience of language.
Apply nowConclusions
The introduction of Parallel Decoding marks a significant leap forward for Machine Translation and Language Models. Their method was published at the “61st Annual Meeting of the Association for Computational Linguistics” (ACL 2023), the world’s top conference in Natural Language Processing, after being recognized by peers as a significant work. World-renewed organizations are already using it in production and building advancements on top of it, illustrating the impact this research has had on the field. The three parallel decoding algorithms (Jacobi Decoding, GS-Jacobi Decoding, and Hybrid GS-Jacobi Decoding) promise not only immediate benefits in terms of speed and efficiency, but also open the door to future advancements in real-time, high-quality technologies for translation, and language generation.
References
Link to the paper: Accelerating Transformer Inference for Translation via Parallel Decoding
Link to the code: Parallel Decoding Library
This blog post is based on the scientific article “Accelerating Transformer Inference for Translation via Parallel Decoding” by Andrea Santilli et al. 2023, from Sapienza University of Rome.

Andrea Santilli
PhD student in NLP @ Sapienza
Researcher in NLP and Language Models: first author of Jacobi Decoding which now doubles LLMs decoding speed (extended and adopted by lmsys); co-author of instruction-tuning (T0) now adopted in every LLM training (including ChatGPT). Contributor to Open Source and Open Science projects (250+ stars on GitHub).

Silvio Severino
NLP Engineer
I am a second-year PhD Student in Natural Language Processing at the Sapienza University of Rome, where I am part of the GLADIA research group, led by prof. Emanuele Rodolà. I spend a lot of time studying Natural Language Processing technologies. In particular, my research fields are Multilinguality, Machine Translation and Geometric Deep Learning.