Language

Michael Leventhal
Founder and Principal Investigator at RobotsMali
After failing at becoming a philosopher, poet, and linguist, Michael Leventhal found middling success in computing, working on knowledge representation, core internet technologies, and novel computing architectures. As one does, he abandoned the fevered plentitude of Silicon Valley, bags laden with tech lore, to work alongside bright and ambitious young Malians in Sahelian-dust-choked fields of opportunity, as they strive to win their nation a place of honor on the world’s stage. RobotsMali AI4D Lab is the fruit of our toil.
In 1956, during the Cold War, Nikita Khrushchev uttered three words that exacerbated tensions and helped set the stage for the Cuban Missile Crisis and the brink of nuclear war. The three words were Мы вас похороним, “We will bury you.” The fate of the world could have rested on this single translation; it has been discussed and debated ever since. похороним is the 1st person plural perfective form of похоронить, to bury, literally, as in to bury a body in the ground. The translation was exact, the debate lies in whether an exact translation masked the more benign intention of the statement. The preceding statement, Нравится вам или нет, но история на нашей стороне, “Whether you like it or not, history is on our side,” suggests that the proper sense of “you” in “We will bury you” is the capitalist system. Had the translator interpreted hardscrabble Khrushchev’s coarse register into the language of diplomats he might have produced “Whether you agree or not, we believe historical trends favor our approach; in time, it will become clear which system proves more resilient” and the course of history might, possibly, have been different.
In this article, I want to explore the same genre of discussion, although in this case, it is the substitution of presumed intent for literalness that risks having geopolitical implications, albeit on a much smaller stage. The translator is an AI, an LLM (ChatGPT, in this case). ChatGPT’s translation is compared to a translation into a second language and to AI translation using the different modality of Google Translate (labelled Neural Machine Translation, NMT). The analysis illustrates much of how an LLM and NMT work, respectively, and the possibility for unfortuitous AI translations to shape our world.
In February 2022, Mali’s government formally asked France to remove its army from its soil, citing a breakdown in cooperation and disagreements over military action against jihadist armed groups. In Mali, the common view is that France’s post-expulsion messaging is retaliatory and an effort to rewrite the story after France’s contribution proved insufficient to check the steady spread of insurgent control. I won’t try to demonstrate intent or orchestration, but I do contend that, prima facie, the French press produces a systematically negative framing of Malian affairs that then circulates widely in the West.
An article was published in the Dutch newspaper De Volkskrant about the RobotsMali project to develop literacy in Malian languages, supported by AI. Although any political dimension of the project is unintended and, in any case, tangential, the journalist chose to frame this work within the political context of French–Malian tensions. We used ChatGPT to take a PDF of the scanned article and translate it into French, our Dutch-language skills sadly lacking. The framing went beyond what the facts support; she made an assertion, rooted in the current atmosphere of disinformation, intentional or not, that would at best be characterized as a pejorative rendering of events.
Here is what she wrote:
Dat neutrale karakter werd met de komst van de junta plotsklaps weggevaagd. De Franse antiterreurmissie Barkhane is opgedoekt, meermaals zijn Fransen opgepakt op verdenking van spionage.
This is how ChatGPT translated the Dutch:
Mais ce caractère “neutre” a été balayé avec l’arrivée de la junte. La mission antiterroriste française Barkhane est partie, de plus en plus de Français sont arrêtés, soupçonnés d’espionnage.
This is my literal translation of the French:
But this “neutral” character [of the French language] was swept away with the arrival of the junta. The French anti-terrorist mission Barkhane has left; more and more French people are being arrested, suspected of espionage.
The French text is striking in its implications. If Malians regularly read the Dutch press, a rendering like this could contribute to an escalation of the already highly inflamed rhetoric and invite further diplomatic friction. In all of 2025, exactly one French national, an embassy employee, was arrested on the charge of conspiracy for espionage, along with accused Malian co-conspirators.
In a personal exchange, the journalist defended herself, pointing to a defective translation: the Dutch word meermaals is equivalent to the French à plusieurs reprises, “on several occasions” in English. While meermaals remains factually questionable when there was one arrest, it is somewhat less charged than “more and more.”
I translated the article again using Google Translate. The result in French is the less offensive “on several occasions”.
Cette neutralité a été brutalement balayée par l’arrivée au pouvoir de la junte. La mission antiterroriste française Barkhane a été dissoute et des ressortissants français ont été arrêtés à plusieurs reprises, soupçonnés d’espionnage.
This neutrality was brutally swept away by the junta’s arrival to power. The French anti-terrorist mission Barkhane was dissolved, and French nationals were arrested on several occasions, suspected of espionage.
The Dutch word plotsklaps is better translated as “suddenly”; the choice of the word “brutally” augments further the somber color of the sentence and the entire article. The accuracy of the translation is debatable. Weggevaagd, the past participle of wegvagen, is “to sweep away” in English, but also “obliterate”, so plotsklaps weggevaagd could stand as “brutally swept away”.
The Google Translate English translation translates the sense of the Dutch text perfectly.
That neutrality was suddenly swept away with the arrival of the junta. The French anti-terrorist mission Barkhane was disbanded, and French nationals were arrested several times on suspicion of espionage
Why does ChatGPT choose to paint an ominous picture of the Malian junta tracking down French people and locking them up as spies? Well, two reasons, because that is what it feels like to French people, and because de plus en plus fits French narrative discourse style much more neatly, i.e., it sounds better.
In French news corpora, the n-gram (a recurring sequence of words) de plus en plus is extremely frequent in political-security reporting. Even in a relatively neutral context without reference to the Malian situation, the model will be conditioned on surrounding tokens (junta, espionage, accused, terrorist, arrested), it may shift probability mass toward high-likelihood escalation templates. This shift is likely to be accentuated once everything is placed in the Malian context, given the preponderance of negative reporting about Mali in the French press — or, as many Malians believe, intentional disinformation. This is the model’s conditional distribution, defined, in the language of mathematics, as:
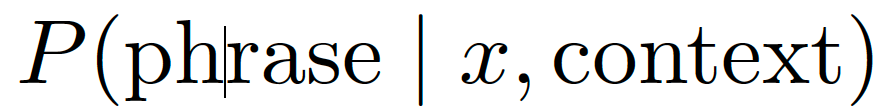
that is, the probability that a phrase will occur, given that we already know the input (the word meermaals) and the surrounding context (the content of the article and the larger context associated with that content). The phrase de plus en plus can have the highest probability because it has strong co-occurrence in the semantic field, even if the lexical anchor meermaals alone maps best to à plusieurs reprises.
In other words, de plus en plus is closer to what French people feel, based on the quantity of reporting that pushed the narrative that Mali is a dangerous place hostile to French people.
One of the most uncanny aspects of LLM-based translation is its ability to produce natural-sounding language, even when the source and target languages express the same idea in very different ways. Achieving this kind of target-language naturalness was a persistent stumbling block for machine translation for decades. De plus en plus is a short, versatile stock phrase. In French journalism, it is often used to suggest rising tension, sometimes even when it is not the best semantic match. It suits the punchy style of the article and reads smoothly—simply sounding better.
Why does Google Translate give us a more sober reading, hewing closely to a literal translation from the Dutch? While LLMs such as ChatGPT and modern NMT AI translators such as Google Translate are often built over the same base architecture (transformers), NMTs are built to do one job extremely well: preserve meaning across languages as directly as possible. LLMs are tuned with a reward technique and human feedback to optimize human preference across many tasks. Their implicit objective is closer to:

which, in plain words, says to tune the model’s parameters so that, on average, its outputs get the highest human preference score. “Reads naturally” can outrank “keep text exactly faithful to what the original text says” unless the prompt explicitly emphasizes literalness. That makes it more willing to introduce discourse-level intensifiers.
NMT models are trained and tuned primarily on parallel corpora (for example, French text with aligned Dutch text) with a translation objective:
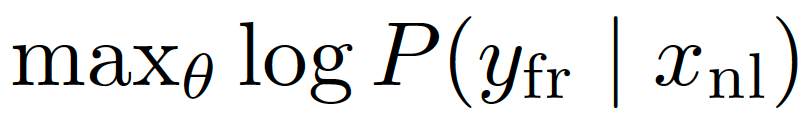
that is, adjust the model parameters θ to make the model assign the highest possible probability to producing the correct French translation yfr given the Dutch input xnl (using log is just a convenient way to work with probabilities during training). Translations that fail to keep text exactly faithful to what the original text says will be strongly penalized by training data and evaluation.
LLMs are built to do many jobs: translate, summarize, rewrite, explain and more while keeping text sounding natural in context. It is the case that, more and more, NMT is converging with LLMs, but even with an LLM substrate NMT will be specifically optimized for adequacy (how well the translation preserves the original meaning) as well as fluency. An adequacy filter can enforce “don’t miss or invent content” through coverage/alignment constraints, use minimum-risk training or reranking to select meaning-preserving outputs, and apply evaluation signals that penalize semantic additions. LLM decoding is not usually guarded by an adequacy filter, but rather aims at a high-fluency output that is not constrained to only what is logically evident from the source.
Why does the LLM stay closer to the literal sense of the Dutch text when translating to English? One possible explanation is that French has more “rhetorical” adverbial templates that are widely used in reporting, and more near-synonyms with subtly different logically implied meanings. The model faces higher lexical choice entropy – that is, there are more plausible, high-probability wordings to choose from – among French options (à plusieurs reprises vs à maintes reprises vs à répétition vs de plus en plus). English has fewer common, idiomatic choices that fit cleanly, so “repeatedly” is an easier, safer mapping.
Does the LLM’s translation lay bare a bias that the journalist had not intended to reveal? Can a translation that is literally wrong be superior for being emotionally true?
With typical decoding (the step where the system turns the model’s word probabilities into an actual translation, usually by picking the most likely next words), the model tends to pick high-frequency, low-perplexity continuations. Here “perplexity” is the model’s own measure of how surprised it would be by a continuation. Lower perplexity means the model finds the continuation more predictable and assigns higher probability to the next words. Higher perplexity means the wording is less expected, so choosing it is riskier. In French, de plus en plus is a very low-perplexity completion once the model has emitted de, because de followed by plus en plus is a frequent fixed idiom. It can then modify many predicate types (e.g., ils sont de plus en plus nombreux, ils sont arrêtés de plus en plus souvent, ils parlent de plus en plus). Once de is produced, decoding can get ‘locked in’ to that high-probability idiomatic path. English “repeatedly” is similarly low-perplexity and also happens to be semantically correct here.
Finally, for everything AI, English is just better. Instruction-tuned LLMs receive more high-quality feedback and fine-grained evaluation on English than on French. Subtle semantic preservation errors in French may be less frequently corrected during RLHF (Reinforcement Learning from Human Feedback, a standard technique for using human preference to weight outcomes), allowing phrases that sound native but misstate the nuance (like de plus en plus) to persist.
Does the LLM’s translation lay bare a bias that the journalist had not intended to reveal? Can a translation that is literally wrong be superior for being emotionally true? Ask a Malian which version matches the accumulated pattern of French coverage, and they will pick de plus en plus without hesitation. Four words, and the sentence stops reporting events and starts reporting a mood of rising menace. In 1956, diplomats rushed to launder Мы вас похороним into something safer, but the world heard the threat. Here, the LLM does the laundering in reverse, obeying its directives for context and fluency to make the threat sharp and keenly felt.