Research
2023 Imminent Research Grants Winning project – Human Computer Interaction Category

Pauline Larrouy-Maestri
Senior researcher in the music department of the Max-Planck Institute for Empirical Aesthetics
Studying the relation between sounds and meaning, Pauline is a classically trained pianist, a speech pathologist, and holds a PhD in cognitive sciences. She is the PI of the team and recipient of the Imminent Award.
A team of researchers from the Max Planck Institute for Empirical Aesthetics combine interdisciplinary expertise to answer these questions with the support of an Imminent grant.
Are we fooled by TTS systems?
To test if we are (still) able to tease apart human and non-human voices, we presented 75 participants with synthetic voices generated with two different TTS systems (Murf, Lovo), as well as with human voices (from the RAVDESS dataset of human vocalizations), speaking the same sentence in different emotional profiles (neutral, happy, sad, angry). Participants were asked to indicate if they suspected some of the voices were generated with a computer and were then asked to sort the stimuli into “human” or “AI-generated”. Even though 76% of participants indicated having suspected some of the voices to be generated with a computer, recognition of AI voices in the categorization task was quite variable (Figure 1). Human voices were recognized as such well above chance level (85.6% correct responses) and synthetic voices were recognized slightly above chance level (proportion of correct responses: 55.2%), which supports that TTS systems were sometimes fooling listeners into perceiving the synthetic voices as human ones.
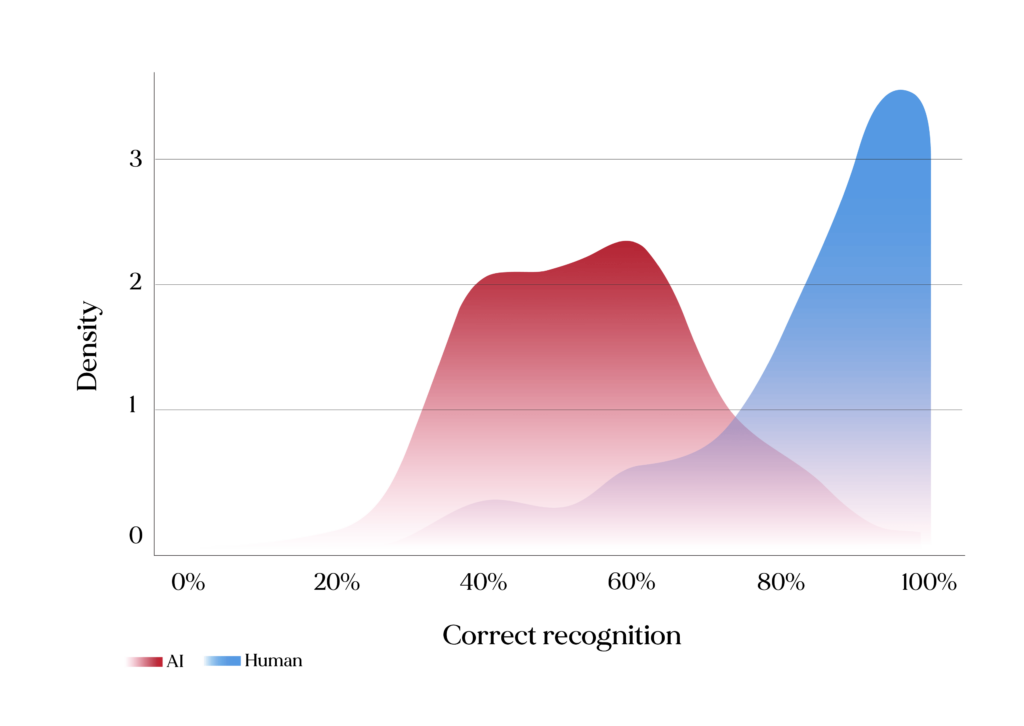
Density distribution of proportion of correct recognition of AI-generated (orange) and human (blue) voices.
Are TTS systems equally good?
The short answer is “no”. In a recent experiment (pre-registration: osf.io/nzd9t), German participants listened to spoken German sentences either recorded from humans or generated by TTS tools (Microsoft, Elevenlabs, Murf, and Listnr). Forty listeners evaluated 1024 speech samples in terms of how human each sample sounded to them. As illustrated in Figure 2, human voices are generally perceived to sound more human than the TTS generated voices. In line with the previous study, the human voices all sound similarly human, but there is a much larger variation among the TTS voices, indicating differences in quality. Of special note are the two voices offered by Elevenlabs, as they generally fool people into thinking they are real humans, with the median humanness rating for these voices above 50 (on a scale ranging from 1 to 100). Interestingly, participants often disagree with each other on how human the voices sound, as highlighted by the large range of colored individual data points in Figure 2.
Humanness rating by voice
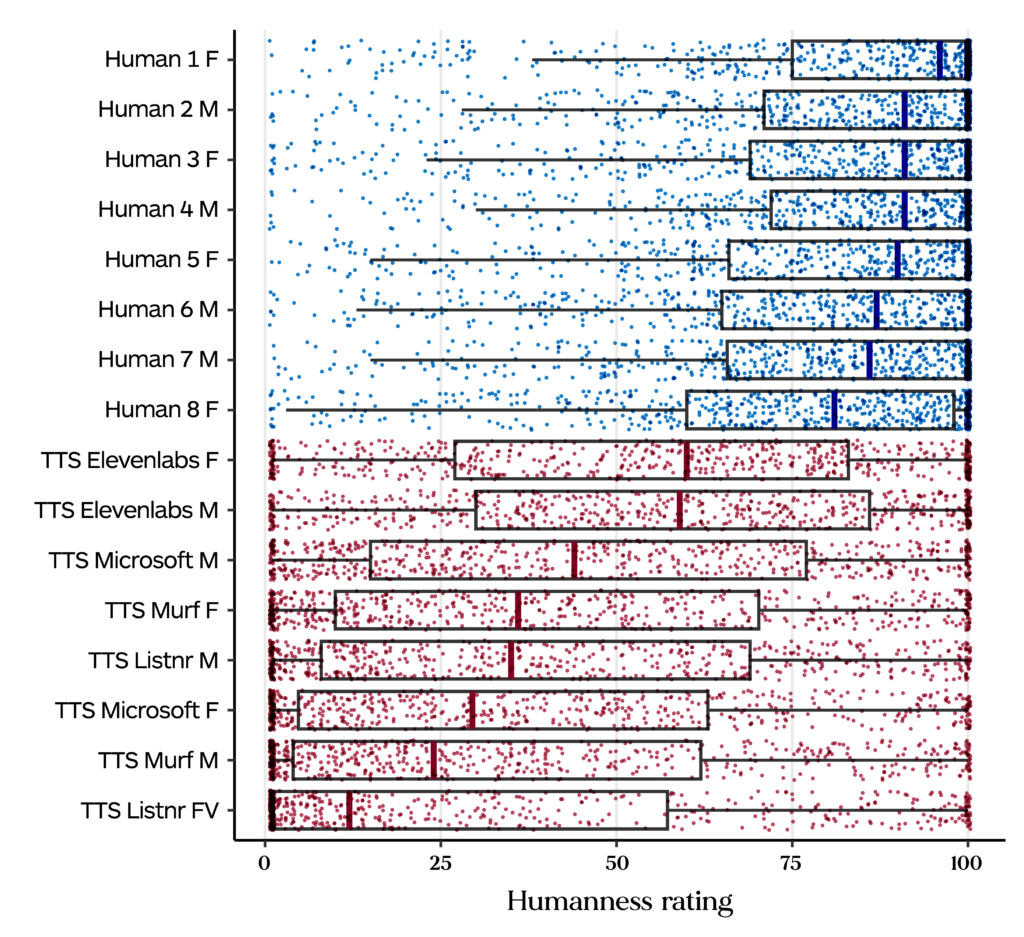
Perceived humanness rating (from 1 to 100) for all 16 voices. M stands for self-reported male and F for self-reported female. Voices are ranked from high to low according to their median humanness rating which is indicated by the thick line within the box. Colored dots indicate individual data points, blue for human voices, orange for TTS voices.
Where does (the lack of) humanness come from?
We can now confidently say that synthetic voices contain cues that enable us to decide that they are not “human” but the nature of these cues remains unclear. Voice quality is of course an important factor. Anyone who has heard the voice of Stephen Hawking, with its specific robotic timbre, can identify it as produced by a computer (or, more specifically, generated by a computer based on the voice of the scientist Dennis Klatt). More generally, the acoustic characteristics of a voice (in terms of timbre but also in terms of pitch and loudness) are important cues that provide information about the speaker’s identity, such as age, gender, or even health. For instance, high pitch voices are generally associated with children’s voices, and pitch typically deepens with age (and associated hormonal changes). It is thus expected that the acoustic profile also provides information about its “humanness”.
Besides voice quality/profile, speech prosody, also called the melody of speech or intonation, is another prominent candidate to cue (non-)humanness of speech. Prosody has a key role in human-to-human interactions, as well as human-to-computer interactions, since it influences how we understand a message as well as how we respond to it. Unfortunately, no precise mapping between prosodic patterns and meaning has been identified so far (e.g., van Rijn & Larrouy-Maestri, 2023, in the case of emotional prosody), but we know that prosody is linked to the syntactic structure of a phrase and the meaning of the words (Cutler et al., 1997). Indeed, the position of the words in a sentence (following grammatical rules), as well as their semantic meaning, affect how we intonate speech.
Focus on speech prosody
To investigate the role of speech prosody, we created various versions of phrases spoken by humans and TTS systems. Some were “normal” (i.e., regular) sentences with both syntactic and semantic information, while others conveyed syntactic but not semantic information (jabberwocky sentences), no syntactic but semantic information (wordlists), or had no syntactic or semantic information (jabberwocky wordlists). As illustrated in Figure 3, the results from forty participants showed the effect of both syntactic and semantic information on humanness perception. Indeed, both TTS and human voices were rated higher in terms of “humanness” when they were speaking normal sentences than in the other stimulus conditions (all p < .01).
Humanness rating by sentence type
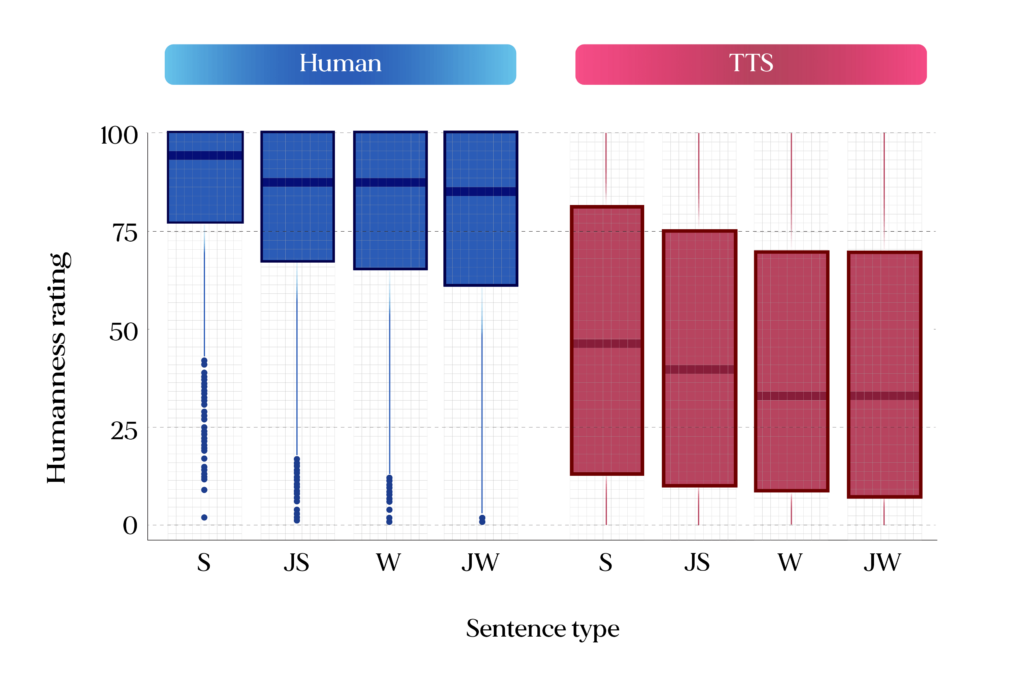
Perceived humanness rating by sentence type for human and TTS separately. TTS voices are perceived as less human than human voices (replication of our previous findings) and regular sentences are perceived as more human regardless of the voice type. S = regular sentences, JS = jabberwocky sentences, W = wordlists, JW = jabberwocky wordlists.
Conclusion and future plans
The findings of this project, supported by an Imminent grant, reveal that people are (still) able to discriminate between human and TTS voices, contrary to what is claimed by AI-supporters. In other words, TTS voices don’t sound exactly human yet and it is thus crucial to figure out if the “lack of humanness” affects how we process speech and more generally our communication abilities. Interestingly, our results also reveal that the quality of the TTS systems (assuming that the highest quality is being able to fool listeners) varies greatly, with some TTS voices clearly recognized as synthetic and others identified as human, and that we are not all similarly sensitive to humanness (i.e., as visible with the large individuals’ variability). Finally, we demonstrated here the role of prosody, in addition to the quality of a voice, in driving listeners’ perception of humanness. The natural next step in our research is to manipulate such factors and examine the neural responses that trigger the perception of (non-)humanness. Ultimately, our research aims to understand how we process these increasingly ubiquitous synthetic voices, to clarify how they might affect us and possibly alleviate negative consequences.
References
Bruder, C., & Larrouy-Maestri, P. (2023, September 06-09). Attractiveness and social appeal of synthetic voices. Paper presented at the 23rd Conference of the European Society for Cognitive Psychology, Porto, Portugal.
Cutler, A., Dahan, D., & Van Donselaar, W. (1997). Prosody in the Comprehension of Spoken Language: A Literature Review. Language and Speech, 40(2), 141–201. https://doi.org/10.1177/002383099704000203
Van Rijn, P., & Larrouy-Maestri, P. (2023). Modeling individual and cross-cultural variation in the mapping of emotions to speech prosody. Nature Human Behavior 7, 386-396. http://doi.org/10.1038/s41562-022-01505-5
Wester, J., & Larrouy-Maestri, P. (2024, July 22). Effect of syntax and semantics on the perception of “humanness” in speech. Retrieved from osf.io/nzd9t
Team members
Neeraj Sharma (https://neerajww.github.io/), collaborator of the team, is a signal processing expert who is an assistant professor at the School of Data Science and Artificial Intelligence, in the Indian Institute of Technology, Guwahati (India).
Camila Bruder With a mixed background in biology and music (she is also a professionally trained classical singer), Camila has recently submitted her PhD dissertation on the topic of singing voice perception.
Janniek Wester Janniek joined the team in 2023 to complete a PhD with a focus on humanness and developed the second experiment presented here.
Acknowledgments: Pamela Breda, Melanie Wald-Fuhrmann, and T. Ata Aydin, for their constructive comments during the development of this project.

Imminent Science Spotlight
Academic lectures for language enthusiasts
Imminent Science Spotlight is a new section where the next wave of language, technology, and Imminent discoveries awaits you. Curated monthly by our team of forward-thinking researchers, this is your go-to space for the latest in academic insight on transformative topics like large language models (LLM), machine translation (MT), text-to-speech, and more. Every article is a deep dive into ideas on the brink of change—handpicked for those who crave what’s next, now.
Discover more here!