
Technology
There is little doubt that 2023 has been the year that Large Language Models (LLMs) have gained widespread attention. This was initially driven by the launch of ChatGPT, which amazed observers by reaching 100 million monthly active users in January 2023, just two months after its launch, making it the fastest-growing consumer application in history. Though the initial explosive growth has tapered down, it’s estimated that ChatGPT still has 100+ million users, and the website sees nearly 1.5 billion visitors per month.
The launch of ChatGPT was followed by a continuous avalanche of open-source models (Llama and Mistral stand out) and a few large private models by Google (Gemini), Baidu, and other Chinese players.
After the initial euphoria, as observers gained more experience with LLMs, we also saw increased criticism listing problems with the technology that includes the following:
- A lack of true understanding can result in shallow and superficial interactions which many could mistake for intelligence.
- A risk of misuse by bad actors who might generate huge volumes of false and misleading information or try to develop malicious tools with the technology.
- LLMs can “hallucinate” or generate plausible but incorrect or nonsensical responses that are not immediately apparent and can also exhibit a serious stereotyping bias triggered by lopsided training data. The “hallucination” problem can be mitigated partially, but not eliminated, and hackers can bypass the guardrails. This limits the possibility of autonomous use in production IT settings.
- LLMs are often described as “black boxes” because we do not fully understand how they generate specific outputs. This lack of transparency complicates efforts to make AI more interpretable, unbiased, and accountable.
- The EU and other governmental agencies have expressed concern over potentially negative societal impacts and ensuring data privacy and security issues. The EU has already introduced initial legislation with the Artificial Intelligence Regulation Act, and there is potential for more proactive regulation in the future.
- There are fears that LLMs could upend education by making it difficult to assign writing tasks that can’t be easily completed by AI. This could also extend to other areas of work where writing is a key component of task completion.
- Training data-related copyright issues have become a much more prominent concern in late 2023 and it seems increasingly likely that the developers of LLMs will have to compensate copyright holders for data that they use to build their foundation models.
However, despite these concerns and issues, there are millions of satisfied users, many of whom are willing to pay a user subscription fee of $20 per month. The two big use cases for Gen AI in 2023 seem to have been coding and marketing. Beyond individual users, many enterprises are using Gen AI for basic coding and marketing-related content generation, copywriting, and generally as a broadly applied writing assistant, or as a means to better assimilate, summarize, organize, and communicate relevant textual information contained in the deluge of content that is common today.
The focus of this article is to examine the capabilities of LLMs to effectively handle the task of language translation where the track record currently is mixed, and while there are promising results, we are still some distance from closing the door on “old NMT technology”.
The ease with which virtually anyone can generate something that “looks like knowledge work” has created a huge amount of hype. Many argue that the ease with which anyone can interact with a huge database of “knowledge” and extract valuable content that could be text, image, or code is what makes these LLMs revolutionary.
The sheer volume of hype across business and social media has also attracted executive attention, and often corporate teams are being asked to use AI where it makes no sense, in scenarios where existing technology is already optimized for efficiency and reliability, and where the introduction of new, poorly understood AI would only introduce additional complexity, increased cost, and inefficiency.
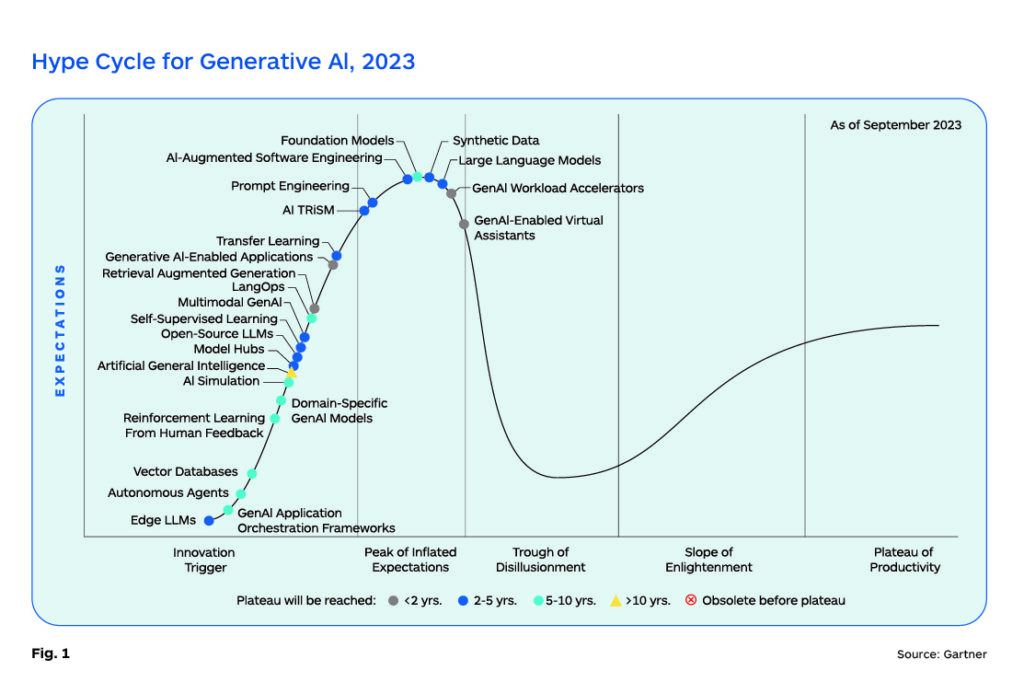
The hype has generated unrealistic expectations, especially in the executive ranks, and Gartner placed Gen AI at the very peak of overinflated expectations in their AI Technology Hype Cycle presentation in August 2023. However, in the more recent Gartner commentary (Fig 1), they say that some variants of language models (Light LLMs, Open-source LLMs) are likely to drive a “Productivity Revolution” in the near term, and that multimodal capabilities are gaining momentum and are likely to become a powerful differentiator.
Nonetheless, we should be careful to not view Gen AI as a single monolithic technology. As we have seen in coding, marketing, and writing assistance tasks, users have found it useful, even revolutionary, and the use of the technology continues to evolve and be refined to increase its suitability for a growing set of use cases.
Therefore, we can already say that some use cases of Gen AI have reached the early stages of the Slope of Enlightenment and that many more use cases could be viable with a human-in-the-loop. The ability to discern where Gen AI can add value to enterprise operations is a more critical and useful skill than over exuberant optimism as we head into the future.
The Multilingual Challenge with LLMs
There are many anecdotal examples of useful tasks being performed by LLMs around localization and translation work. LLM-based tools can help knowledge workers complete a variety of tasks more quickly and increase output quality. Current LLMs perform best in English and are already useful in cleaning English source data before it is translated, LLMs are also helpful as post-editing assistants and there is some success in partially automating the PEMT task. These incremental improvements are valuable but have yet to be implemented for operational efficiency at scale. Initial experience with LLMs reveals that they perform best with English and other “high-resource” languages.
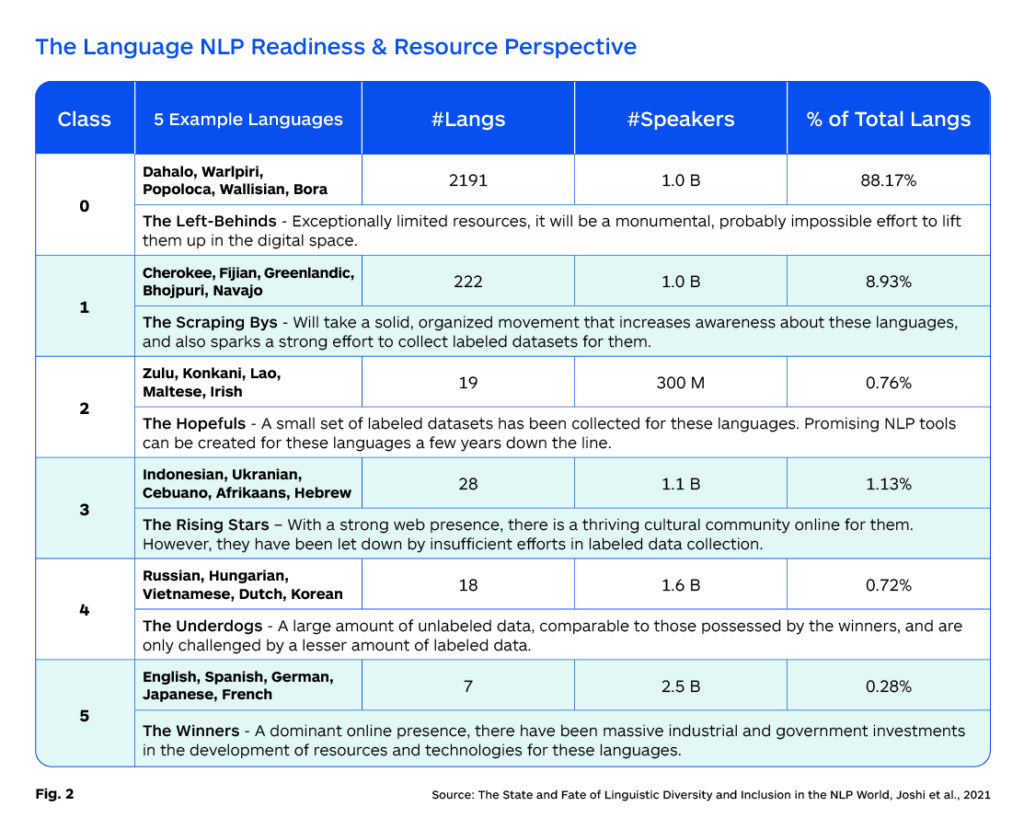
While an overwhelming majority of the data used to train most of the LLM models today is English, we have seen that they can also perform translations of high-resource languages quite effectively. This is true despite a very low volume of non-English language data within the training data. Given the monumentally high costs of training foundation models, it is unlikely that LLMs can be easily updated for multilingual capabilities in the near term, but initiatives are underway. A closer examination of the “NLP Readiness” of diverse languages is shown in the following chart and described in more detail in The State and Fate of Linguistic Diversity and Inclusion in the NLP World.
For languages to be viable in an LLM or any NLP application, it is necessary to have adequate volumes of training data. While some NLP use cases can be effectively built from relatively small volumes of monolingual data, generally translation models require millions of bilingual data points for successful results.
Low-resource languages have been an ongoing focus and concern for the NMT development community over the last few years. While there has been some success in this effort, the quality of NMT model performance beyond the top 60 or so languages is noticeably lower.
NMT-focused research produced the Transformer algorithm that is the algorithmic foundation for LLMs, and many are now asking if new LLM-based approaches could provide a pathway to broader language coverage by creating synthetic data that leverages available data. There is active research underway to explore if small volumes of data (both monolingual and bilingual) could be used to expand language coverage to Class 0 languages as described below. But the reality is, that for the foreseeable future, we are likely to see little progress beyond Class 5 and Class 4 languages, and perhaps to a limited extent with some Class 3 languages. Efforts are underway to expand coverage, but this will likely take years.
Multilingual LLMs will reduce the barriers to information access and help realize transformative applications at scale. The English bias of leading LLMs creates formidable obstacles for many non-English speakers. For example, GPT-4’s performance is still best in English, and its performance drops substantially as we move to mid and low-resource languages. And to add insult to injury, the cost is also often higher.
Translated has attempted to improve and equalize the LLM user experience for non-English speakers with the T-LM service, where MT is used as a bridge to improve LLM results. Intento analysis in March 2024 showed that several LLMs produce up to 3X better accuracy on summarization task results by using MT to interact with the models, and in general, English-based interactions produce better results.
Since the cost of using LLMs is generally based on tokens, it is more expensive to use GPT-4 in any language other than English. In the context of LLMs, tokens can be thought of as units of text that the models process and generate. It involves segmenting the raw text into meaningful units to capture its semantic and syntactic structure. They can represent individual characters, words, subwords, or even larger linguistic units. Tokens are the bridge between the raw text data and the numerical representations that LLMs can work with internally.
Figure 3 shows how much the tokenization and thus cost can vary by language. Because of this tokenization penalty on non-English interactions, it is often necessary for these users to translate prompts into English and translate the responses back into their preferred language to both keep costs down and get higher-quality responses. This process adds procedural friction and also reduces the quality of the results.
LLM Translation Quality Performance in 2023
In general, it is fair to say that LLMs have a fluency edge over most generic NMT systems, especially when translating into English. Most of the comparative LLM vs NMT evaluations done in 2023 point this out, and also state that performance often falls short in translation into non-English languages, and is much worse in low-resource languages. Lack of relevant linguistic and societal context in languages and cultures where English is not prevalent will also impact translation task-level performance for LLMs.
With expert engineering efforts, generative AI models can match the translation quality of top Machine Translation (NMT) models in a small set of high-resource languages. This equivalence is measured by automated scoring methodologies which assess the semantic similarity of machine output to human translations. However, the relative performance of the machine in comparison to human quality drops significantly in specialized fields or domains like Legal or Healthcare.
Early evaluations also noted that while LLMs have a better document-level contextual sense, they are also much more likely to make semantic or meaning errors and much more likely to produce hallucinations (confabulations) within the translations they produce. While there is quality parity at times, the improvement of LLMs over NMT is small and not yet compelling, except perhaps for badly formed source data like user-generated content (UGC) where greater improvement is observed.
However, this status quo is dynamic and as skilled engineers learn to steer LLMs better to perform a translation task, we see ongoing improvements in translation quality performance.
LLM-based translation pipelines are more challenging to implement in production deployments because the models can also produce extraneous suggestions that are vaguely related but not needed for the specific translation task at hand, and thus currently the most professional use of the technology is in interactive prompt-response chat modes. This is a serious limiting factor in enabling LLMs to become a preferred automated translation production technology (Fig 4).

The interactive prompt-response based mode of operation allows grammatical error corrections to be performed on the source as a pre-translation task that enables better translation. LLMs are also useful for performing automated translation evaluation tasks, rankings, and automated post-editing tasks.
In general, the performance of LLMs tends to be better when translating into English, and less compelling when translating into other languages. There is also broad evidence suggesting that LLM translations perform better than NMT models with poorly formed source text that is typical of user-generated content. Some promising evaluations were presented at the WMT23 conference, considered the most established benchmark in the field, and the results are summarized below (Fig. 5).
The research on overcoming the identified obstacles to production deployment of LLM translation models is ongoing and is expected to start bearing fruit in 2024. The status quo in 2025 could be quite different. While initial attempts in the localization industry at fine-tuning private LLMs involve crude prompt-based tuning with large chunks of translation memory and terminology, the process and the results are inefficient, erratic, and inconsistent. Additionally, model performance in terms of latency and throughput is significantly slower than equivalent NMT models. This prevents the broad use of these kinds of systems in serious production deployments.
However, the outlook for those working with open-source models appears to be more promising. More skillful developers, like the team at Translated, are exploring open-source models like Llama-3, Mistral, Mixtral 8x22B, and GPT-4o, and others are seeing more consistent and reliable translation performance through continued pre-training and a variety of sophisticated, supervised fine-tuning techniques. This includes careful filtering and optimal selection of fine-tuning data, Retrieval-Augmented Generation (RAG), Direct Preference Optimization (DPO), and cheaper, faster model training techniques.
There are also efforts to reduce complexity and model size to improve performance in production scenarios. The continuing flurry of new models is both an opportunity and a challenge for developers as obsolescence is a constant shadow lurking in the background. It is difficult and expensive to repeatedly redo all the pre-training and fine-tuning work on each new “amazing” model that emerges. Thus, deep expertise and competence will be required to make strategic long-term model selection decisions. Enterprise buyers seek robust, consistent, and efficient solutions, and most people are tired of the never-ending parade of new models.

Advantages of LLMs over Neural MT Models
- LLMs provide a basic adaptive model infrastructure that has the potential to improve over time as they continue to learn from user interactions.
- LLMs tend to produce more fluent text, especially going into English.
- LLMs are capable of zero-shot learning, meaning they can perform tasks they haven’t been explicitly trained on, and few-shot learning, where they can adapt to new tasks with minimal examples.
- LLMs excel at capturing long-range dependencies, which helps them understand how words relate to each other over longer distances within the text.
- LLMs can be fine-tuned to adapt to varying contexts, such as different business verticals, and align with the expected tone of voice and choice of words, thus reducing the cost of post-editing and accelerating translation delivery.
- LLMs are more capable of picking up the specific patterns of language variants in languages like English, Spanish, French, and Arabic.
- LLMs are evolving and widespread research on improving multilingual capabilities could result in breakthroughs that address many of the current challenges.
Disadvantages of LLMs compared to Neural MT Models
- There is a limited set of high-resource languages where LLM models can meet or beat NMT model performance.
- LLMs may struggle with domain-specific translations due to their training in general text, which can be a disadvantage when specialized knowledge is required.
- LLMs are sensitive to prompts, which means the way a question or command is phrased can significantly affect the model’s response and performance.
- Training and running LLMs require significant computational power, which can be expensive and resource-intensive.
- LLMs are still very slow to run and cannot be used in high-volume translation production scenarios due to very high latency.
- LLMs lack controllability, meaning their responses to specific inputs cannot be easily directed or controlled.
- LLMs can sometimes generate plausible but inaccurate responses, known as hallucinations, especially when they encounter nuanced or ambiguous queries.
- While LLMs have an understanding of immediate and explicit context, they often falter when it comes to understanding larger or implicit context within a text.
- LLMs are sometimes trained on multiple language pairs simultaneously, which can dilute their proficiency in any single specific pair.
Understanding the Major Structural Challenges Ahead
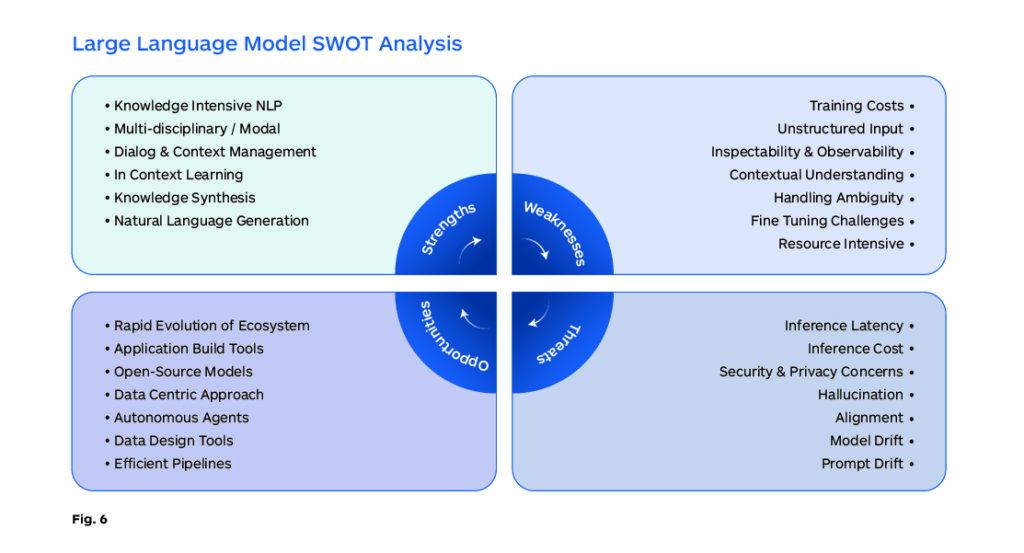
The gating factors for continued progress with the current Transformer-based AI technology are scarce computing resources, limited data availability, and expertise scarcities. There is research and exploration across the globe into bringing LLM-based technology into mainstream enterprise and personal productivity applications. However, there are challenges both in the development and the deployment of this technology as summarized below (Fig. 6).
Because the training costs for building LLM models are substantial, training cannot be done often and requires a major computing resource investment. This critical startup cost and obstacle also limits the number of new, innovative development strategies that can be tested. It is well understood that larger models do tend to deliver better performance, but they are more expensive to train and run slower.
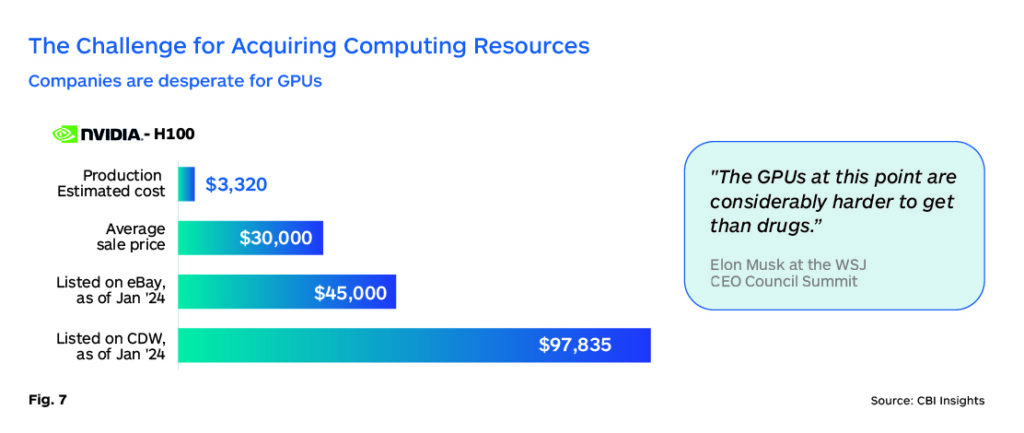
The demand for GPUs is now so great that there is a black market in which commonly used GPUs are selling at 50% to 300% markups. In February 2024, customer demand for Nvidia (the primary supplier of GPUs with an 85+% share) was so far above supply that the CEO had to publicly discuss how ‘fairly’ the company decides who can buy them.
The GPU scarcity problem is not likely to change in the near term as the manufacturing is complex and fabrication for new manufacturing plants is time-consuming and expensive. AMD, Intel, and smaller competitors do exist, but they will need time to have a meaningful impact on the current supply imbalance. However, users understand that the largest costsare with inference and are seeking new ways to reduce these costs. Inference costs are being driven down by third parties like Groq and Together.ai. ASICs and custom development by hyperscalers could also put a dent in Nvidia’s advantage. As hyperscalers increasingly design their specialized chips optimized for inference, they reduce reliance on general-purpose AI hardware from external suppliers. (Fig. 7).
The other key element required to improve LLMs is large volumes of high-quality data that can be used to train and further enhance the models. The distinction between high-quality and low-quality data is crucial for training effective LLMs. High-quality data typically comes from sources that have undergone some form of quality control, such as peer-reviewed scientific papers, published novels, and curated websites. In contrast, low-quality data may include unfiltered, user-generated content from social media or comments on websites, which can introduce noise, bias, and spurious correlations into the training process.
The challenge lies not only in the sheer volume of data required but also in ensuring that this data is of sufficient quality to train models that can generate coherent, accurate, and unbiased outputs. There are already some who claim we are reaching the limits on high-quality original data and that the future will require increasing amounts of synthetic data. This issue may be even more pronounced in languages other than English or the top 10 resourced languages (Fig. 8).
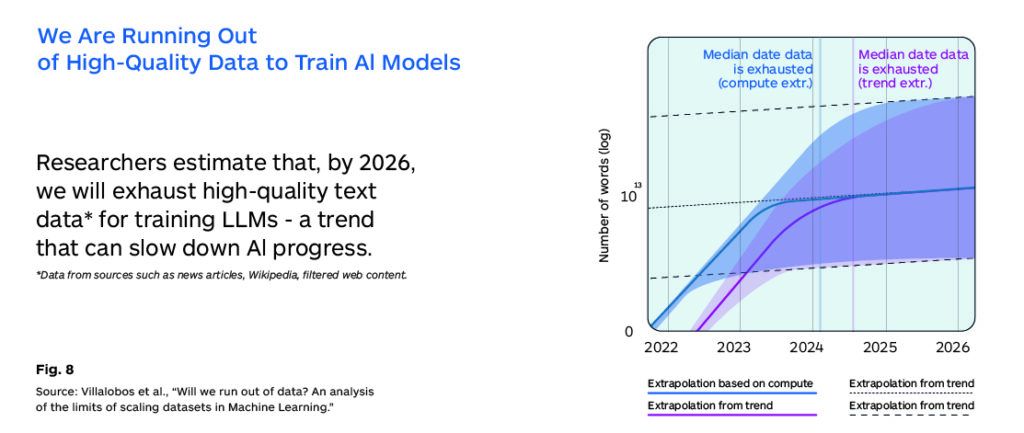
This implies that continued progress may need to come from “synthetic data.” One approach involves generating high-quality training data from existing LLMs, using techniques like the “self-instruct” method, where an LLM generates training data for itself based on its responses. This can potentially create a feedback loop that improves the quality of the training data without the need for constant human intervention. But this comes with many risks and model decay is also a possible outcome.
Humans will need to provide oversight to monitor and limit bias and discrimination, reduce privacy violations, and minimize financial and reputational risks. While synthetic data presents a valuable opportunity to enhance the training of LLMs, addressing the potential consequences requires careful consideration of the ethical, privacy, and bias implications. By implementing responsible data practices and mitigation strategies, the benefits of synthetic data can be realized while minimizing its challenges.
Additionally, the development of models like Llama 3, which are designed to be more efficient and require less computational power, indicates a trend toward creating more accessible and sustainable LLMs.
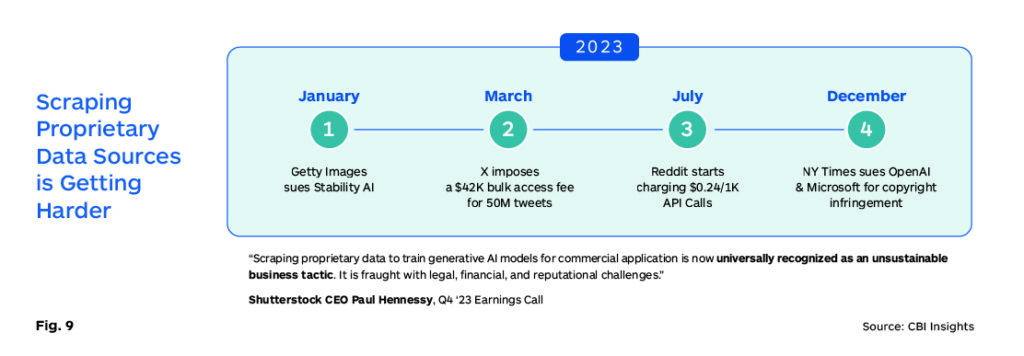
It is now increasingly understood that scraping data is not an acceptable practice. In 2024, Reddit signed a $60M agreement to let Google use its data for training AI models. “The data-sharing arrangement is also highly significant for Google, which is hungry for access to human-written material it can use to train its AI models to improve their “understanding” of the world and thus their ability to provide relevant answers to questions in a conversational format.” (Fig. 9)
Many developers have stated that the single most desirable advancement would be a more efficient way for a model to learn. Since more data will not be easily available, gleaning the most from the available data would be the most desirable research breakthrough.
It may also perhaps be that the world is now ready and eager to move beyond Transformer technology. Mamba, a potentially more efficient training and inference engine is one initiative that points to a post-Transformer world, and research is underway.
Understanding the Operational Challenges
For enterprise MT customers, in addition to data security and systems integration issues, the most important operational decision criteria are the following:
- Translation Quality and Robustness: This could be measured with automated benchmarks (e.g. COMET). Preferably, users should use evaluation texts that are as close as possible to real use cases to get accurate assessments.
- Latency: the delay between sending in the source-language sentence and receiving the translated target-language sentence. This is a measurement of system responsiveness and does not include the additional existing overhead which consists of the time taken to construct the prompt that includes querying translation memories, running inference on the LLM, and extracting the target sentence from the response. The p99 latency is the upper time bound it takes to translate 99% of sentences from a benchmark evaluation set.
- Price: in MT, this is most commonly measured in $ per 1M source characters, independently of the language. LLM vendors generally have a token-based pricing model where they count the tokens used in the prompt (input) and the response (output) and often price the input and output tokens differently. Token counts vary greatly by language making them a problematic basis for the LLM MT scenario. Customers familiar with the “$ per million characters” approach that has been in effect for over a decade will find token-based pricing difficult to estimate, understand, and plan around.
The three criteria listed above are often in a trade-off relationship. For example, translation quality can be improved by increasing latency and price, or latency can be improved but may cause a reduction in quality.
Current challenges to work towards production LLM MT deployment include the following:
For LLM MT vendors, costs are driven by the unit price of the underlying LLM, with considerable variation between some commercial, closed-model LLMs such as GPT-4o and open-weight LLMs such as Mixtral 8x22B or Llama 3. Using open-source solutions may require additional setup, as well as ongoing infrastructure management and maintenance costs.
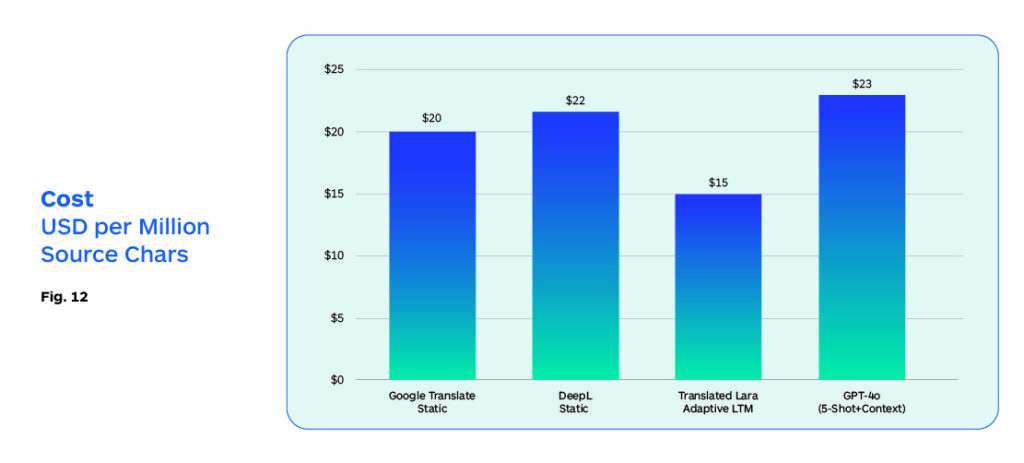
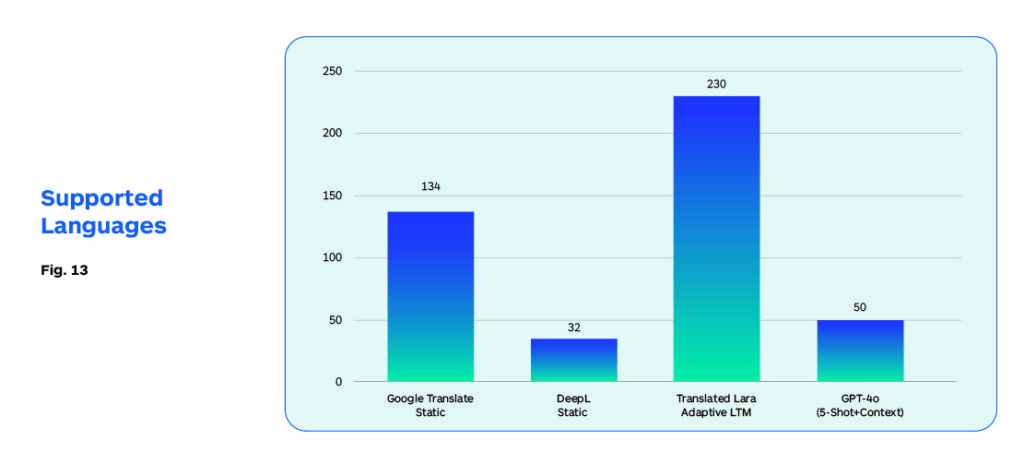
Figures 10 to 13 present experiments conducted by Translated in May 2024 measuring each of these indicators for a range of alternatives.
The contending models are encoder-decoder Transformer models:
- Google Translate API
- DeepLo Pro API
and LLM-based models:
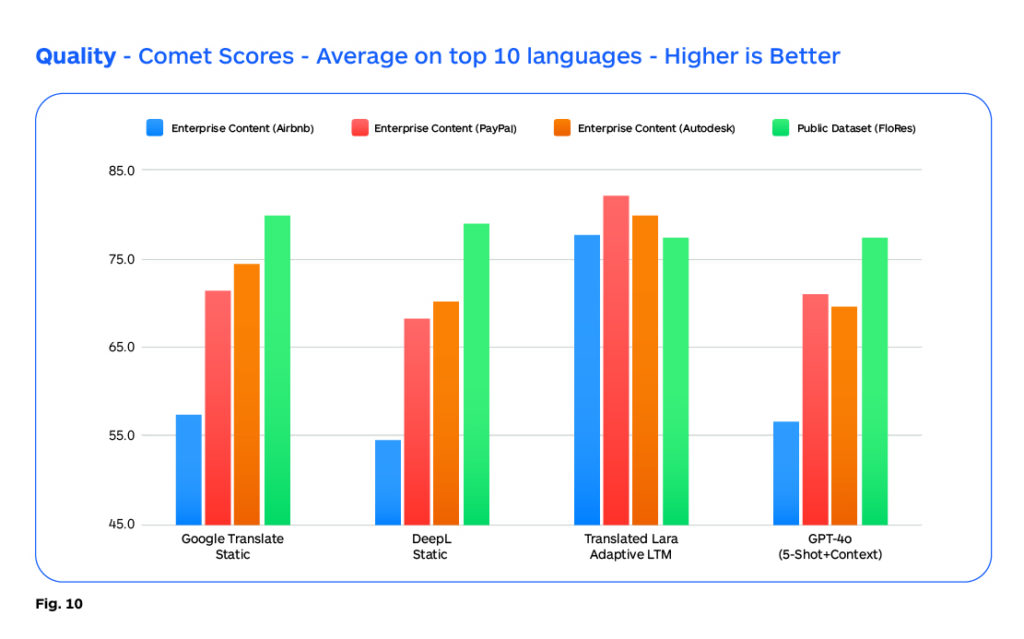
COMET scores provide a rough estimation of translation quality in active research settings, as shown below, however, these scores are not accurate in an absolute sense and need to be validated by professional human translator assessments whose interpretation of score differences is more useful and meaningful to understanding the overall quality implications. Major public NMT engines tend to score well with public datasets like Flores as there is a high probability that they have trained on this data.
While quality is an important determinant of MT system selection, other factors like, available language selection, cost, and latency discussed previously, are often more important to system selection in enterprise deployment settings.
The research analysis at Translated shown in the chart below, compares the performance of these systems with both typical and specific “enterprise content”, as well as with widely available public content. The evidence shows that “properly primed” LLM MT models can consistently outperform SOTA NMT models, at least in high-resource languages.
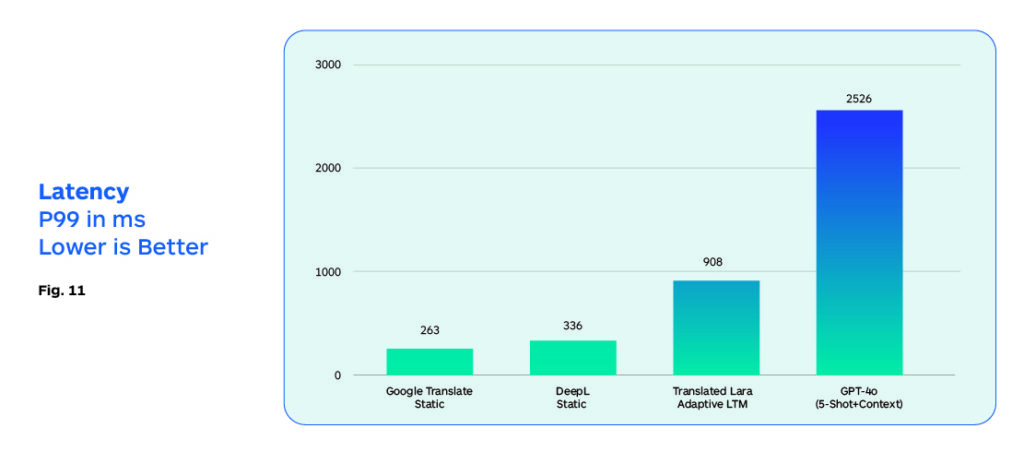
High latency is possibly the single most serious obstacle to the widespread deployment of LLM translation models. So, while current models can be useful to translators who can interact with the LLM through prompts that may take multiple seconds to return a translation, this is not viable in a production translation workflow.
However, as we mentioned, there are several initiatives underway that focus on reducing the inference costs e.g. third parties like Groq and Together.ai. Groq’s website describes its LPUs, or “language processing units,” as “a new type of assessments whose interpretation of score differences is end-to-end processing unit system that provides the fastest inference for computationally intensive applications with a sequential component to them, such as AI language applications (LLMs).” Groq is also interesting because it appears to address the latency problem better. Analysts claim it is 4X to 8X faster than many of its competitors. This is still well short of NMT system performance, which would still be 25X faster.
Translated Lara performs best on costs, quality and latency, and will generate cost savings in production enterprise settings as it will require less human oversight and corrective efforts.
The following data provides additional information on the key parameters of cost, latency, and throughput across several leading LLMs.
Thus, a language translation developer focused on developing a pure LLM-based translation solution that would be cost, quality, and latency performance-wise competitive with current production NMT models, appears to be within reach. If not in the immediate near term, it is quite likely within a 12-to-15-month time frame.
The ability to fine-tune quickly and efficiently in the customer domain will be an additional gating factor in addition to integration into production translation workflows. Thus, while these are all difficult challenges, we should not be surprised to see pure LLM translation by the end of 2024, at least for the top 10 high-resource languages.
But for broader language coverage, we will still need to depend on traditional NMT systems that already provide some capability in 200+ languages. Some form of hybrid configuration may provide the best ROI during the next 12-18 months as the resolution to the latency issues is still some distance away.
The Growing Multilingual and International LLM Community
An April 2024 report by the Stanford University HAI Institute surveyed the LLM landscape and pointed out the US Tech companies’ dominance of the field. While two-thirds of models released last year were open-source, the highest-performing models came from commercial entities with closed systems. Google alone released a whopping 18 foundation models in 2023. For comparison, OpenAI released seven, Meta released 11, and Hugging Face released four. Overall, U.S. companies released 62 notable machine learning models last year compared to 15 coming out of China, eight from France, five from Germany, and four from Canada.
LLM models produced by these US companies are the most widely used today and though they have some multilingual capabilities, they offer the best experience for English-speaking users. Again, “high-resource” languages perform better in some LLMs, but the data resourcefulness gap contributes directly to two specific harms: inequitable outcomes and disparate impacts on non-English speakers, and circumvention of English-language safety interventions. Private technology companies in the US that build language AI are not incentivized to invest in lower-resource language development because it incurs high costs and offers only marginal commercial upside.
Equivalent performance across language has not been a design goal for any of the LLMs developed in the US. Developers outside of the US are the most invested in developing more robust and capable multilingual LLMs. Non-US initiatives do face a data scarcity problem, and thus the models that are being developed by many countries are smaller. Often the first step in improving performance in other languages is to improve the tokenizer and develop new custom capabilities that are more efficient and accurate in other languages.
Here is a selected overview of international initiatives that have a strong multilingual or non-English perspective.
France
A company started by ex-Meta employees has emerged as a significant competitor in the AI field, particularly with its development of LLMs that rival GPT-4. Mistral AI has focused on providing a European alternative to powerful AI models developed in the US. Mistral models are designed to be multilingual from the ground up. Mistral Large, for example, is fluent in five languages: French, English, German, Spanish, and Italian. Mistral has launched its own AI chatbot, Le Chat, available in beta, which functions similarly to ChatGPT but with the added capability of understanding multiple languages. Their models are well-regarded among open-source options and are also known to be more efficient. A recent partnership with Microsoft will enable them to offer their models on the Azure platform.
Cedille, developed by the digital agency Coteries, provides a game-changing solution for French-speaking users. It is the largest publicly accessible French-speaking LLM to date, achieving a perplexity score that is significantly better than GPT-4.
BLOOM is a collaborative project with volunteers from 70+ countries and researchers from Hugging Face. BLOOM is one of the most powerful open-source LLMs, claiming the capability to provide coherent and accurate text in 46 languages.
Italy
Modello Italia is the first Italian LLM created by iGenius and Cineca. This initiative aims to help companies and public administrations leverage Gen AI in critical areas such as healthcare, finance, and national security. It is guided by the highest compliance, privacy, and national security regulations and will be released as open-source.
Fauno is the largest open-source Italian conversational LLM. It demonstrates that obtaining a fine-tuned conversational bot with a single GPU is possible. Fastweb, an Italian telecom provider, has also stated that they will build LLMs to cater specifically to the Italian language.
Real AI won a project to build Europe’s first human-centric open-source LLM using the Leonardo supercomputer in Italy.
Recently, Minerva was created by the Sapienza NLP research group, is the first LLM trained from scratch in Italian. The distinguishing feature of the Minerva models is that they have been built and trained from scratch using open-access texts using 500 billion Italian and English language words, also built on the Leonardo supercomputer and expected to be available for public access shortly.
Scandinavia
Researchers at AI Sweden and the Research Institutes of Sweden (RISE) addressed the dearth of data by taking advantage of the fact that Swedish is typologically similar to the other languages in the North Germanic language family. By taking data in Swedish, Norwegian, Danish, and Icelandic, they have access to sizable amounts of data. They have successfully developed GPT-SW3, an LLM that is specifically designed for the Nordic languages, with a primary focus on Swedish. They are now working on developing multimodal models.
TrustLLM is another Swedish initiative with a focus on Germanic languages that can serve as a blueprint for future activities in other families of languages.
Silo, a Finnish company, released a multilingual Finnish-English LLM called Poro that is competitive with Meta’s opensource Llama models. Silo has built Poro in collaboration with the University of Turku, and now plans to train a range of models across all European languages. The company has access to data from an EU-funded initiative called The High-Performance Language Technologies (HPLT) project that, since 2022, has gathered 7 petabytes (7,000 terabytes) of language data across 80 languages. For context, GPT-3.5 (the model that powered the release version of ChatGPT) was trained on 45 terabytes of text data. Silo has made its model multilingual by “cross-training” the model with English and Finnish data. This means that the model is fed text in both languages, and it then learns itself how the two languages relate to each other. This means you can ask it things in Finnish, and it’ll give you an answer in Finnish, even if it has to draw on English training data.
Slavic languages
Aleksa Gordic, ex-DeepMind and the founder of Runa AI, has unveiled YugoGPT, a robust generative language model tailored specifically for Serbian, Croatian, Bosnian, and Montenegrin. YugoGPT is touted as the largest generative language model for these languages and aims to offer a versatile AI assistant capable of understanding a text, answering questions, and addressing the unique needs of individuals and businesses in the BCMS-speaking nations.
Middle East
Aramco, Saudi Arabia’s national oil company, announced a 250 billion parameter large language model they claim is the world’s largest industrial LLM. Called METABRAIN, the AI model was trained on 7 trillion data tokens of public and internal Aramco data, based on about 90 years of data.
The technology company Watad has announced Mulhem, the first Saudi Arabia domain-specific LLM trained exclusively on Saudi data sets. The 7 billion parameter AI model was developed and trained on 90 billion Arabic and 90 billion English data tokens. By focusing on a model trained exclusively with local data, Mulhem is expected to have enhanced effectiveness in understanding and generating language that resonates with cultural and contextual nuances specific to Saudi Arabia. This makes it particularly valuable for applications in sectors like customer service, automated translations, and perhaps even in governmental communications where understanding local dialects and nuances is crucial.
The government of Saudi Arabia plans to put $1 billion behind GAIA, its generative AI startup accelerator program. Falcon, from the Technology Innovation Institute in the United Arab Emirates, has two highly regarded LLMs that have performed well on open-source leaderboards.
The JAIS Large Language Model (LLM) is tailored for Arabic and was also developed in the United Arab Emirates (UAE). The model is open-source and available for download on the Hugging Face platform. Currently considered among the foremost Arabic LLMs, Jais, a 13-billion parameter model, was trained on a newly developed 395-billion-token Arabic and English dataset on Condor Galaxy, one of the largest cloud AI supercomputers in the world, launched by G42 and Cerebras in July 2023 using 116 billion Arabic tokens and 279 billion English tokens, it has continued to improve. Significant attention was devoted to pre-processing Arabic text, enhancing support for the language’s unique features, including its writing style and word order. Jais also maintains a balanced Arabic-English dataset focus for optimal performance, offering a marked improvement over models with a limited Arabic text presence. Its developers say Jais, unlike other models, captures linguistic nuances and comprehends various Arabic dialects and cultural references. Microsoft invested $1.5 billion in Abu Dhabi’s G42 to accelerate AI development and global expansion in April 2024. This strategic investment will enhance the UAE’s position as a global AI hub and provide further opportunities for partners and customers to innovate and grow.
India
The poor support for Indic languages in open-source models, due to the scarcity of high-quality Indic language content and inefficient tokenization in models like GPT-3.5/4 has resulted in several initiatives across India. Data collection initiatives like Bhashini will also facilitate research and provide fuel for better models in the future. These include:
- Sarvam AI working in collaboration with AI4Bharat, to develop the “OpenHathi Series” and release the first Hindi LLM from the series, showing GPT-3.5-like performance in Indic languages with a frugal budget.
- Reliance Industries’ Jio Platforms has partnered with Nvidia to build an LLM trained in India’s diverse languages.
- AI4 Bharat’s Nilekani Centre at IIT Madras: has collected over 21 billion open text tokens and 230 million open parallel sentences in various Indian languages. They have also gathered 100,000 hours of YouTube videos in Indian languages under a Creative Commons license.
- BharatGPT Hanooman is an emerging LLM developed by Reliance and Bombay IIT. It is trained across 22 Indian languages and includes multimodal capabilities. The first four models in the series, with 1.5B, 7B, 13B, and 40B parameters, will be released in March 2024 and will be open-sourced.
China
On August 31, 2023, China officially sanctioned its first roster of 11 LLMs, marking a significant step in the country’s AI development strategy. Industry giants such as Baidu, Tencent Holdings, and Huawei were among the key players to receive the government’s endorsement. More recently another 40 LLM initiatives were approved.
Baidu’s Ernie (Enhanced Representation through Knowledge Integration) chatbot was released in September 2023 and has garnered more than 100 million users by February 2024, but it’s restricted to users with a Chinese telephone number.
Tencent has focused on enterprise applications with its Hunyuan LLM, claiming it to be more capable than some of the leading US models. Tencent’s approach reflects a strategic emphasis on leveraging LLMs for business and enterprise solutions, rather than consumer-facing products.
Beijing Academy of AI (BAAI) is at the forefront of LLM development in China, with projects like WuDao, CogView, and Aquila. These open-source models demonstrate BAAI’s commitment to advancing LLM technology and making it accessible for further innovation.
Singapore
Singapore launched a S$70 million National Multimodal LLM Programme to develop Southeast Asia’s first regional LLM that understands the region’s languages and context. The initiative will build on current efforts from AISG’s Southeast Asian Languages in One Network (SEA-LION), which is an open-source LLM that the government agency said is designed to be smaller, flexible, and faster compared to LLMs in the market today. SEA-LION currently runs on two base models: a three billion parameter model, and a seven billion parameter model. AISG said: “Existing LLMs display strong bias in terms of cultural values, political beliefs, and social attitudes. This is due to the training data, especially those scraped from the internet, which often has disproportionately large WEIRD-based origins. WEIRD refers to Western, Educated, Industrialized, Rich, Democratic societies. People of non-WEIRD origin are less likely to be literate, to use the internet, and to have their output easily accessed.”
SEA-LION aims to establish LLMs that better represent “non-WEIRD” populations. Its training data comprise 981 billion language tokens, which AISG defines as fragments of words created from breaking down text during the tokenization process. These fragments include 623 billion English tokens, 128 billion Southeast Asia tokens, and 91 billion Chinese tokens.
Massively multilingual models
Cohere for AI, recently introduced Aya, an open-source LLM trained on the most extensive multilingual dataset to date, supporting 101 languages. They also released the Aya dataset, a corresponding collection of human annotations. This offers a large-scale repository of high-quality language data for developers and researchers. The new model and dataset are meant to help “researchers unlock the powerful potential of LLMs for dozens of languages and cultures largely ignored by most advanced models on the market today.” The Aya model surpasses the best open-source models, such as mT0 and Bloomz, in performance on benchmark tests “by a wide margin,” and expands coverage to more than 50 previously unserved languages, including Somali and Uzbek.
PolyLM is an open-source ‘polyglot’ LLM that focuses on addressing the challenges of low-resource languages by offering adaptation capabilities. It “knows” over 16 languages. It enables models trained on high-resource languages to be fine-tuned for low-resource languages with limited data. This flexibility makes LLMs more useful in different language situations and tasks.
BigTrans is a project that has augmented LLaMA-13B with multilingual translation capability in over 100 languages, including Chinese, by continually training with massive monolingual data and a large-scale parallel dataset. It is available on GitHub.
The mT5 (massively multilingual Text-to-Text Transfer Transformer) was developed by Google AI. It is a state-of-the-art multilingual LLM that can handle 101 languages, ranging from widely spoken Spanish and Chinese to less-resourced languages like Basque and Quechua. It also excels at multilingual tasks like translation, summarization, question-and-answering, etc.
We should expect that there will be an increasing number of multilingual LLM models released in the coming future, and while they will likely be much smaller than the Big Tech models we see today, they are likely to outperform the big models for users who engage in regional languages and seek a higher level of cultural and linguistic compliance from LLM model output.
The Way Forward to Production Ready LLM MT
With the introduction of any disruptive technology, there are always questions raised about the continued viability of the previous generation of technology. When data-driven MT technology was first introduced, many said that TM would disappear. But we have seen that it has only become more strategic and valuable across three generations (SMT > NMT > LLM) of MT technology. The rise of electric vehicles has not resulted in the immediate demise of internal combustion engine cars. While the trend is clear, technology replacement is generally slow for pervasive technology. MT is a pervasive, ubiquitous technology that is used by hundreds of millions of people every day. Additionally, during these transitions, there is often an opportunity for hybrid forms of the technology to also flourishduring the transitional period as we see with cars today.
The obstacles to the pervasive deployment of LLM-based translation models listed below are significant, and these factors will work in tandem to slow LLM momentum and delay the point at which it becomes compelling to switch from NMT to LLM. Some of these obstacles could be overcome in as little as six months but some may take years.
Adaptability
Today’s adaptive NMT models can be instantly tuned to meet unique domain and customer-specific needs. LLM models perform well in generic performance comparisons but lag in domain-specific use cases. LLM tuning requires larger context windows. LLMs with larger context lengths require more memory and processing power, resulting in increased inference latency (slower response). The relationship between tokens scales quadratically as context length grows. The expectation is that there will be a dramatic increase in the size of context windows so that entire TMs can be loaded more efficiently than is currently possible with current prompt technology. However, today’s on-the-fly adaptation is clumsy and still difficult to automate.
Complexity of Adaptation
The fine-tuning process is more complex, less consistent, and less reliable than with NMT models. Loading TM chunks into prompts has minimal or unpredictable impact on quality, as most novices find, but for a select few making the intensive engineering effort, sophisticated fine-tuning yields some success. New approaches using knowledge graphs, retrieval augmented generation (RAG), vector databases, and direct preference optimization (DPO) may mitigate thesedifficulties to some extent, and ongoing research efforts may soon yield breakthroughs.
Language Coverage & Training Data Scarcity
Translation-focused Transformer models seem to learn best from high-quality bilingual text. This data exists only for 25 high-resource languages. NMT has also struggled with low-resource languages but is available in 200+ languages today. However, the larger volumes required by LLMs will slow progress in expanding multilingual capabilities unless reliable synthetic data creation becomes viable.
GPU Shortage & Scarcity
This slows down research that could potentially produce more efficient, smaller footprint models. The cost of exploration and bias toward very large models also limits the research to the few who have access to these expensive resources.
Copyright Issues
This has triggered litigation for OpenAI, and already Google has set a precedent by buying the right to use copyrighted data. Negative resolution on current litigation and unforeseen costs related to the use of copyrighted material could slow progress. In May 2024 France’s Autorité de la Concurrence announced a staggering €250 million fine against Google which has reignited discussions surrounding copyright protections in the digital age. At the heart of the matter lies the competition watchdog’s assertion that Google violated previous commitments to fairly compensate news publishers for the use of their content – a charge that underscores the delicate balance between intellectual property rights and corporate conduct in the digital realm.
Integration and Deployment Ease
LLM latency prohibits it from being deployed in translation production workflows. The need for human oversight also limits the use of LLM MT in autonomous workflows, thus it is currently best suited for lower volume, HITL, refinement-focused kinds of use scenarios.
Fundamentally, LLM-based machine translation will need to be more secure, reliable, consistent, predictable, and efficient for it to be a serious contender to replace state-of-the-art (SOTA) NMT models.
Thus, SOTA Neural MT models may continue to dominate MT use in any enterprise production scenarios for the next 12- 18 months. We are probably looking at scenarios where LLM MT might also be used in settings where high throughput, high volume, and a high degree of automation are not a requirement.
There are many translators focused on high-resource languages who already find that ChatGPT, Gemini, and CoPilot are useful productivity aids in interactive use modes that allow evolving refinement, and where hallucinations and unexpected results can be handled more easily with ongoing oversight.
It is the author’s opinion that there is a transition period where it is quite plausible that both NMT and LLM MT might be used together or separately for different tasks. NMT will likely perform high-volume, time-critical production work as shown in the chart (Fig.15).
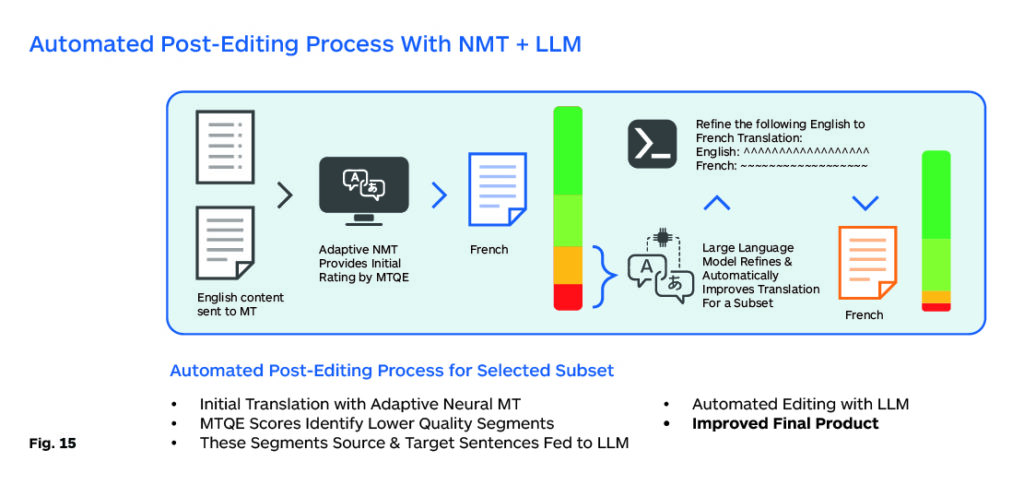
In this scenario, information triage is at work. High-volume production work is done by an adaptive NMT model, and an efficient MTQE process then sends a smaller subset to an LLM for cleanup and refinement. These corrections are then sent back to improve the MT model and increase the quality of the MTQE.
However, as LLMs get faster and it is easier to automate sequences of tasks, it may be possible to embed both an initial quality assessment and an automated post-editing step together for the LLM to manage. This can then be validated by a human in the loop to ensure that all the highest-quality data is fed back (Fig.16).
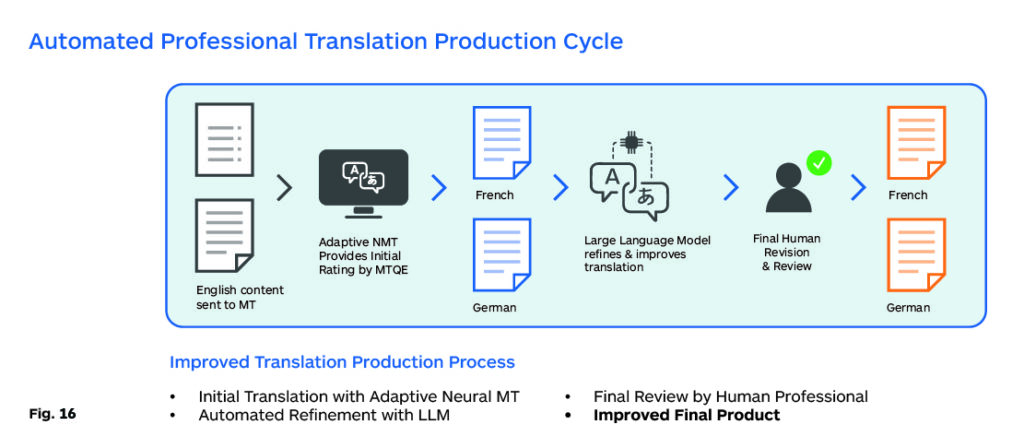
When several of the factors listed previously are resolved, especially latency and straightforward adaptability, it may be possible to start phasing out NMT, at least for high-resource languages. This article has focused on the translation task, but LLMs can also be used for a variety of other translation ancillary tasks that involve classification, text quality verification, source preparation for translation, tagging, and organization of textual dataflows.
It may be possible to build a series of generalization-capable agents that perform critical translation workflow tasks across a range of use cases and work together to build a continuously improving production cycle as shown in Fig. 20.
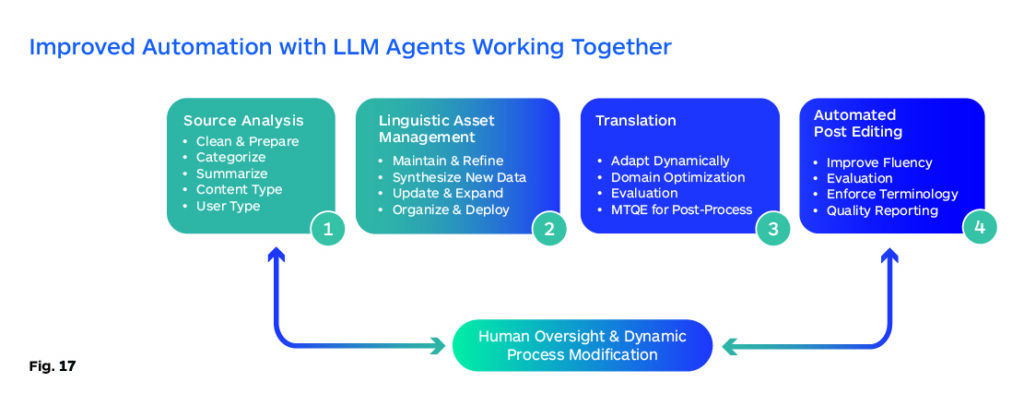
A thriving and vibrant open-source community will be a key requirement for ongoing progress. The open-source community has been continually improving the capabilities of smaller models and challenging the notion that scale is all you need. It would be unfortunate if the momentum shifts only to massively larger models, as this would result in a handful of companies dominating the LLM landscape.
But all signs point to an exciting future where the capabilities of technology to enhance and improve human communication and understanding can only improve, and we are likely to see major advances in bringing an increasing portion of humanity into the digital sphere in productive, positive engagement and interaction.

Kirti Vashee
Language technology evangelist at Translated
Kirti Vashee is a Language Technology Evangelist at Translated Srl, and was previously an Independent Consultant focusing on MT and Translation Technology. Kirti has been involved with MT for almost 20 years, starting with the pioneering use of Statistical MT in the early 2000s. He was formerly associated with several MT developers including Language Weaver, RWS/SDL, Systran, and Asia Online. He has long-term experience in the MT technology arena and prior to that worked for several software companies including, Lotus, Legato, & EMC. He is the moderator of the "Inner Circle" Automated Language Translation (MT) group with almost 11,000 members in LinkedIn, and also a former board member of AMTA (American Machine Translation Association). He is active on Twitter (@kvashee) and is the Editor and Chief Contributor to a respected blog that focuses on MT, AI and Translation Automation and Industry related issues.