
Technology
We live in an era where the major challenges and problems we face are increasingly global in nature and scope. The ability of humans to solve complex problems is greatly influenced by the ability of diverse groups be- ing able to communicate effectively, so it is now acknowledged that machine translation technology will be a key contributor to improved dialog across the globe on issues beyond accelerating international commerce. A recent long-term study conducted by Translated SRL has shown that MT capabilities are now approaching the singularity. This is the point at which other humans often consider machine output to be as good as expert human translation. The sheer scale of this study described in more de- tail later in this article is cause for optimism in many areas where language is a barrier to communication. As MT continues to improve and expand in capability, it will be- come a tool for fostering greater understanding and co- operation among nations, businesses, and people. We will explore the following topics to provide the larger context and importance of this increasingly important technology:
- The importance of collaboration in solving existential global crises
- The continuing improvements in linguistic AI and its likely impact on better communication and collaboration in the commercial, government, and humanitarian sectors
- The changing global marketplace and the need for con- tinued expansion of MT capabilities into the languages of the rapidly growing and increasingly more important emerging world economies
- The state of MT in relation to other emerging Language AI such as Large Language Models (LLM)
- The evolution of the human-machine relationship as Language AI technology evolves in capabilities and competence
Solving global human challenges requires a more global perspective, and there is a growing understanding that these problems are best solved with a broad international community perspective that contributes to the understanding of the multifaceted problems we face, and then builds global cooperation to develop potential solutions. The three most pressing global problems we face today as a human species, most will agree are:
- Global Warming / Climate Change
- Managing Emergent Pandemic & Disease Scenarios
- Poverty Reduction & Eradication
Understanding and developing solutions to these problems will require cooperation, collaboration, and communication among groups scattered across the globe on an unprecedented scale. We know that there are many individuals and organizations are already working to address climate change and its impacts with some limited success. These include governments, international organizations, NGOs, and private sector companies, as well as scientists, policymakers, and concerned citizens. The crisis is significant and will require a collaborative effort that is equal in scale, intensity, and innovation.
The COVID pandemic and the increasing incidence of cli- mate-related disasters across the world provide clear evidence that the problem is already here, and that it is in all our interests to work together to address these challenges in a unified manner. Nation-based efforts can work to some extent but the interconnected and interdependent nature of the modern world requires a much more collaborative and globally coordinated response if we as a species are to be successful in our response.
This does not necessarily mean that a new global organization will coordinate all action, as we also know that sharing knowledge of best practices among globally dispersed grassroots groups and initiatives can also contribute meaningfully to progress in addressing these challenges. The crisis is serious enough that we need both centralized global initiatives and local efforts working in a coordinated and mutually reinforcing way.
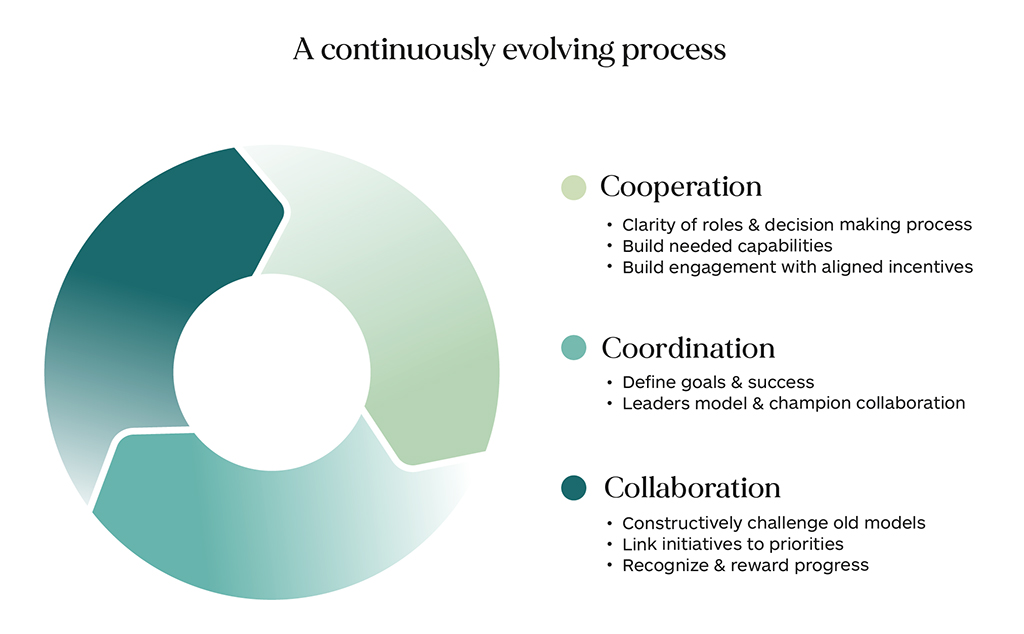
The importance of collaboration
But to move forward, there must be communication and collaboration at the highest levels. The term collaboration is often used, and it is important to understand what it means when used in this context. What do we mean by collaboration? The typical business definition of the term refers to “individuals from multiple teams, groups, functions or business units who share responsibility and work together on an initiative to achieve a common goal.” The ability to form a unified collective with a common purpose seems to be a key requirement.
Experts who study successful collaborative initiatives point to the existence of an ongoing and continuously evolving process, that takes place over time, and that is refined and improved with experience. Success is unlikely to come from simply coordinating team structures or by simply making sequential handoffs of work products between teams. Moving from a functional mindset to a committed adoption of shared goals is seen as a much more likely driver of successful collaboration. People need a shared understanding of why something is important and why they are doing it. They want to know what the benefits of taking special measures are to be able to build deep commitment.
The expert recommendations given for building effective collaboration would be challenging to implement even in a single organizational context where everyone speaks the same language, has a strong common cultural foundation, and has a clearly defined power hierarchy. The challenge of collaboration becomes exponentially more difficult when we add different languages, different cultural values, and different levels of economic well-being.
However, the tools, processes, and procedures available to facilitate and reduce friction continue to evolve and improve, and technology can assist in the fundamental communication process needed to enable disparate groups to rally around a common purpose and collaborate on solution strategies to address these unrelenting global challenges.
The growing impact of linguistic AI technology
The technology underlying language AI has made great strides in the last decade, and there is even reason to believe that for some very specific tasks, natural language processing (NLP) technology may be able to perform some at near human levels of competence.
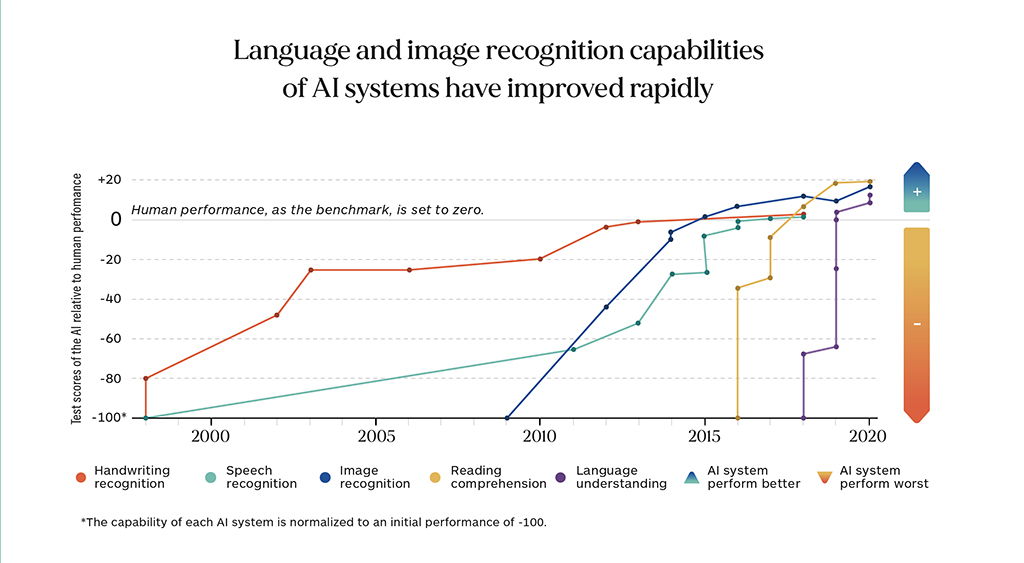
If we are to believe the benchmarks being used to assess linguistic AI competence, we are already approaching human-like performance in many areas. However, many critics and skeptics have shown that while there has indeed been much progress, the commonly used benchmarks only measure very narrow aspects of the tasks they perform and that the claims fall short in many real-world scenarios. Experts have demonstrated that computers do not comprehend, understand, or have any meaningful cognition about the data that they generate and extrapolate. The term “stochastic parrot” has often been used to describe what linguistic AI does, and there is a growing body of documented examples of failures showing that AI can be deceptively fluent in its glibness, and thus requires careful expert oversight when used in any real-world scenario. Today, many of the most successful implementations of linguistic AI technology include a robust human-in-the-loop process.
This suggests that claims of human performance based on widely used benchmark scores are unlikely to stand up to scrutiny. We have yet to properly define “human competence” in many cognitive tasks to allow for accurate and robust measurement. Thus, we should take a chart like the one below with a very large grain of salt, and skepticism is advised before any unsupervised production use of any of the technologies listed below.
One of the most useful Language AI technologies is automatic machine translation (MT). Today, MT is used daily by hundreds of millions of users around the world to understand and access knowledge, access entertainment, and commercial content that is only available in a language that the user does not speak or understand. However, even with MT, we see that “raw” MT must be used with care by the enterprise, and the best results in production-MT-use are achieved when properly designed human-in-the-loop interventions are implemented in an MT workflow.
The Increasing Value of Machine Translation
While MT has improved significantly over the last decade, most experts caution against claiming that MT is a complete replacement for human translation services. Like many of the best linguistic AI technologies available, MT is an assistive technology and can significantly improve the performance and productivity of expert human translators. However, MT should only be used as a full replacement for human translation when the cost of failure is low, or when the volume is so large that no other means of translation would be viable. And, even then, machine output needs to be monitored regularly to identify and correct egregious and dangerous errors of misinformation or hallucination that can occur with any linguistic AI.
With all these caveats in mind, we should also understand that MT technology will play a fundamental role in expanding any global collaboration to address the major global problems that we have outlined. When properly deployed, MT can help to massively scale communication and knowledge sharing to dramatically reduce the impact of language barriers. MT technology can add value in all of the following areas:
- Knowledge sharing (sharing of institutional knowledge across industries, government to citizens, and science and technology content)
- Knowledge access (cross-lingual search and access to knowledge resources that are concentrated in a few languages)
- Communication (real-time formal and informal (chat) text communication across languages, but increasingly extending to audiovisual communication)
- Audiovisual content (educational, entertainment, and business content which increasingly is delivered through video presentations)
- Information Gathering (monitoring of social media commentary to identify key trends, issues, and concerns among user populations)
- Entertainment and ad-hoc communication on social media platforms.
- MT can enhance cross-lingual communication at scale, and improve cross-lingual listening, understanding, and sharing in ways that are simply not possible otherwise. As the planet approaches a global online population of around 5 billion people, the requirements for useful MT are changing. Today, there is a much greater need for usable MT systems for so-called “low-resource” languages.
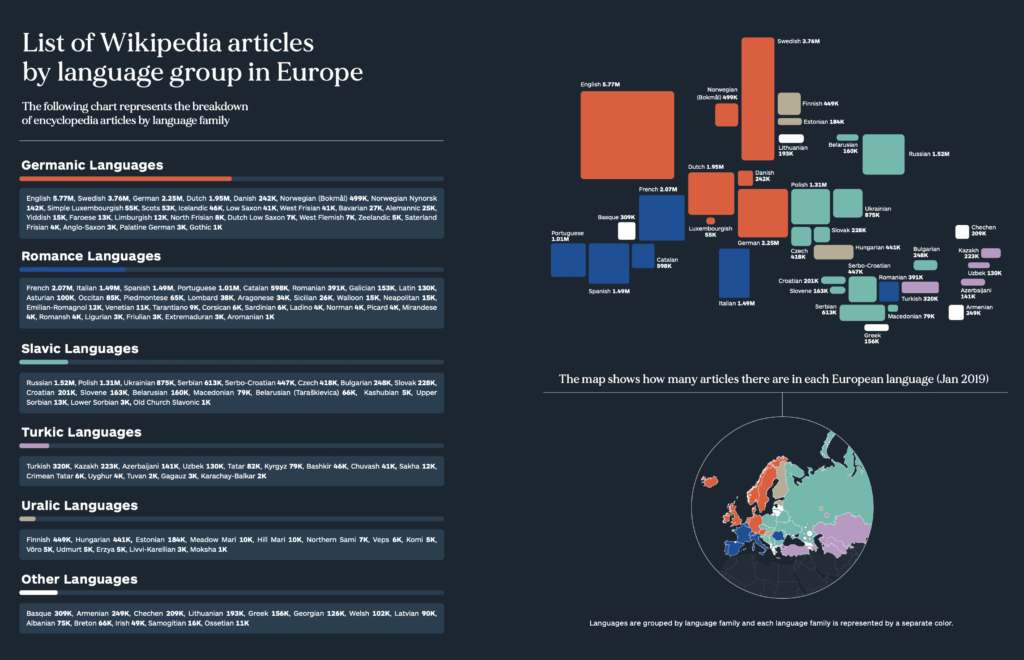
If we look at the evolution of the Internet, we see that for much of the early period, the Internet was English-dominated, and much of the early non-English speaking user population faced a kind of linguistic isolation. This has changed over the last decade and the dominance of English continues to decline, as more and more new content is introduced in other languages. But it will take longer to change the relative amount of high-quality information already available in each language. English has had a head start and has had more investment over decades, especially in science, technology, and general knowledge, building a large foundational core that is not easily matched by any other language. If we take Wikipedia as a rough proxy for freely available high-quality information in a language, we can see that the size of the English Wikipedia as measured by the number of articles, the number of words, and the size of the database, among other things, is much larger than other languages. As of 2019, the English Wikipedia was still three times larger than the next largest languages: German and French. The chart below gives a rough idea of the linguistic distribution of “open-source knowledge” by language group and shows the concentration of available resources by language.
{kind=link}
Machine translation is a technology that enables access to digital information on a large scale. As such, machine translation is a critical technology for extending access to quality information to larger groups of people who may be linguistically disadvantaged. Not only does it enable them to access valuable knowledge resources to improve their lives, but it also enables a more diverse population to participate in a global collaborative effort to address existential challenges.
More than a decade ago prescient social commentators like Ethan Zuckerman said:
“For the Internet to fulfill its most ambitious promises, we need to recognize translation as one of the core challenges to an open, shared, and collectively governed Internet. Many of us share a vision of the Internet as a place where the good ideas of any person, in any country, can influence thought and opinion around the world. This vision can only be realized if we accept the challenge of a polyglot internet and build tools and systems to bridge and translate between the hundreds of languages represented online.”
It can be said that mass machine translation is not a translation of a work, per se, but it is rather, a liberation of the constraints of language in the discovery of knowledge. Access to information, or the lack of access creates a particular kind of poverty. While we in the West face a glut of information, much of the world still faces information poverty. The cost of this lack of access to information can be high.
The World Health Organization estimates that an estimated 15 million babies are born prematurely each year and that complications of preterm birth are the leading cause of death among children under the age of 5, accounting for approximately 1 million deaths in 2015. “80% of the premature deaths in the developing world are due to lack of information,” said the University of Limerick President Prof. Don Barry. The non-profit organization Water.org estimates that one child dies every two minutes from a water-related disease, and nearly 1 million people die each year from water, sanitation, and hygiene-related diseases that could be reduced with access to safe water or sanitation and/or information on how to achieve it.
Much of the world’s knowledge is created and remains in a handful of languages, inaccessible to most who don’t speak these languages. The widespread availability of continuously improving MT helps increase access to critical information produced around the world.
Access to knowledge is one of the keys to economic prosperity. Automated translation is one of the technologies that offers a way to reduce the digital divide, and raise living standards around the world. As imperfect as MT may be, this technology may even be the key to greatly accelerating real people-to-people contact around the globe.
Much of the funding for the development of machine translation technology has come from government organizations in the US and Europe. US military-sponsored research originally focused on English <> Russian systems during the Cold War, and later helped to accelerate the commercialization of statistical MT (based on original IBM research), this time with a special focus on English <> Arabic and English <> Chinese systems. The EU provided large amounts of translation memory corpus for EU languages (training data) to encourage research and experimentation and was the main supporter of Moses, an open-source SMT toolkit that encouraged and enabled the proliferation of SMT systems in the 2008 – 2015 period.
Statistical MT has now been superseded by Neural MT (NMT) technology, and almost all the new research is focused exclusively on the NMT area. Because NMT uses deep learning machine learning techniques similar to those used in AI research in many other areas, MT has also acquired a much closer relationship to mainstream AI and NLP technology initiatives which are much more publicized and in the public eye.
The development of modern Neural MT systems requires substantial resources in terms of data, computing, and machine learning expertise. Specifically, it requires a linguistic data corpus (bilingual text for preferred language combinations), specialized (GPU) computing resources capable of processing large amounts of training data, and state-of-the-art algorithms managed by experts with a deep understanding of the GPU computing platforms and algorithmic variants being used.
As the scale of resources required by “massively multilingual” approaches increases, it also means that research advances in NMT are likely to be increasingly limited to Big Tech initiatives, and it will be difficult for academia and smaller players to muster the resources needed to participate in ongoing research on their own. This could mean that Big Tech’s business priorities may take precedence over more altruistic goals, but early indications suggest that there is enough overlap in these different goals that progress by one group will be of benefit to both. Fortunately, some of the Big Tech players (Meta AI) are making much of their well-funded research, data, and models available to the public as open-source, allowing for further experimentation and refinement.
The Changing Global Opportunity Outlook
The forces behind the increased investment in the development of MT systems for low-resource languages are twofold: altruistic efforts to develop MT systems to assist in humanitarian crises, and the interests of large global corporations who recognize that the most lucrative commercial opportunities in the next decade will require the ability to communicate and share content at scale in the languages of these new emerging markets.
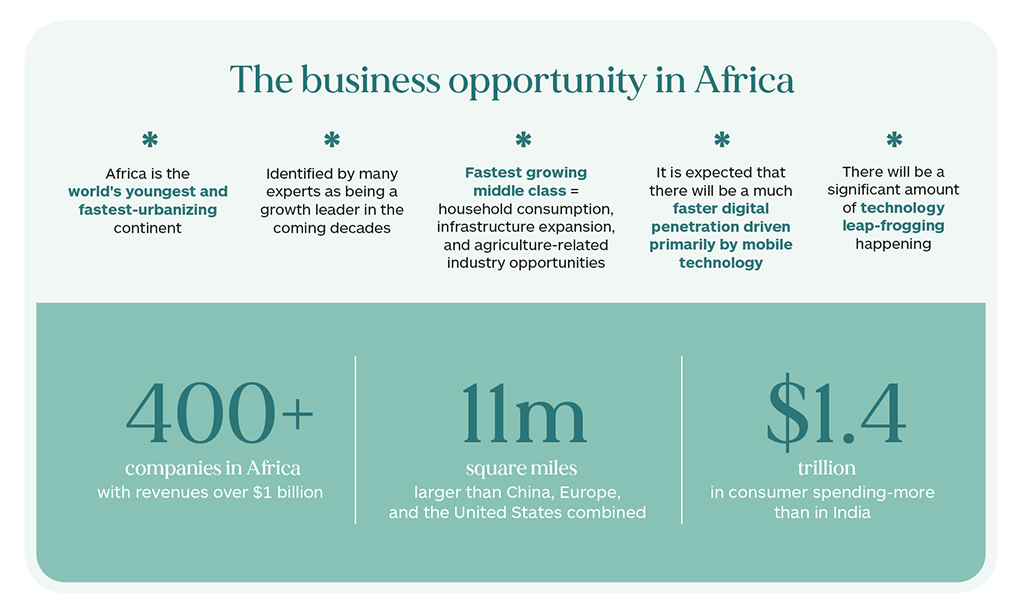
The most successful results with MT technology to date have been with English-centric combinations with the major European languages (PFIGS) and to a lesser extent the major Asian languages (Chinese, Japanese, and Korean). Continued improvements in these languages are of course welcome, but there is a much more urgent need to develop systems for the emerging markets which are growing faster and represent the greatest market opportunity for the next few decades. The economic evidence of Africa’s rapid growth and business opportunity is clear, and we should expect to see the region join South Asia as one of the most lucrative growth market opportunities in the world in the future.
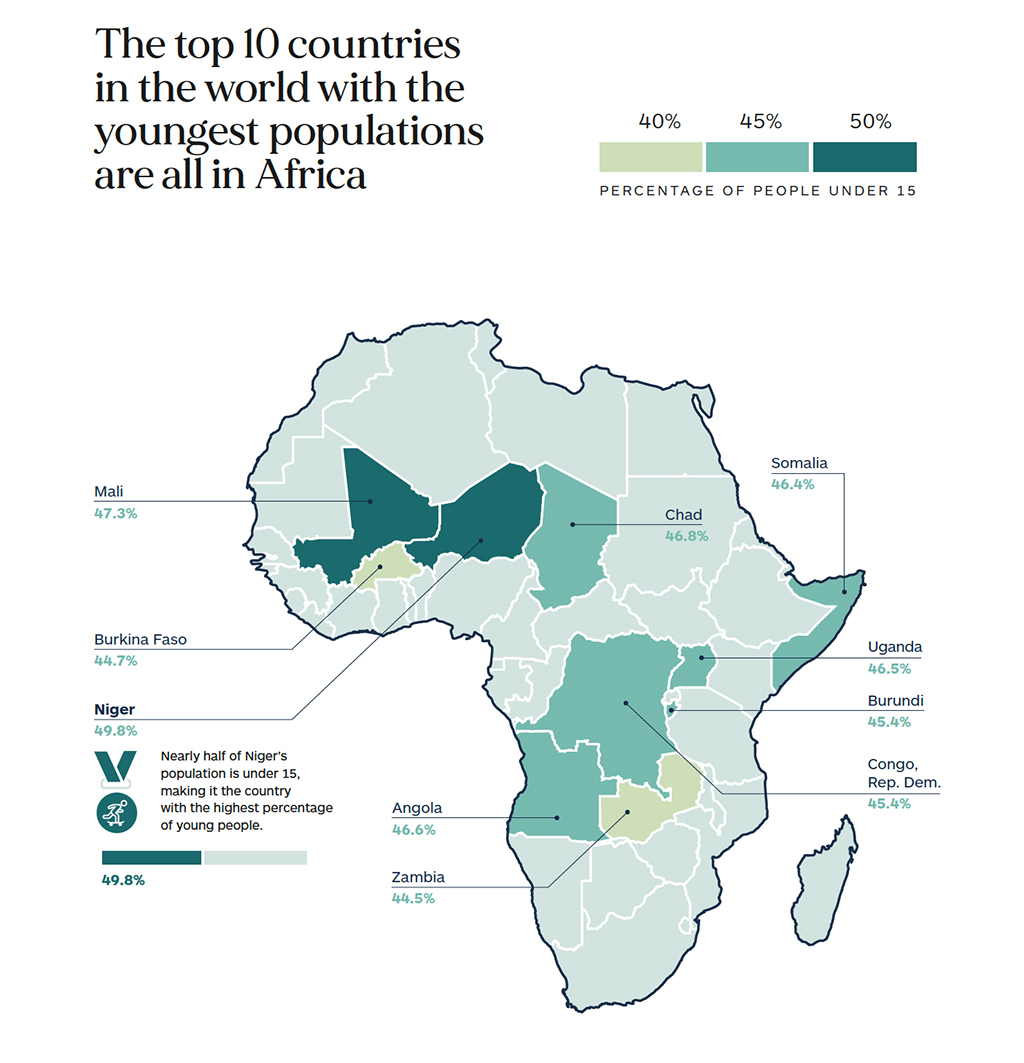
“Demography is destiny” is a phrase that suggests that the size, growth, and structure of a nation’s population determine its long-term social, economic, and political fabric. The phrase underscores the role of demography in shaping the many complex challenges and opportunities facing societies, including several related to economic growth and development. However, it is an exaggeration to say that demography determines everything. Nevertheless, it is fair to say that in countries with a growing elderly population, where an increasing proportion of the population is leaving the workforce and moving into retirement, there is likely to be an impact on the economic dynamism of that country. Fewer young people in a population means that there is a smaller workforce on the horizon, a shrinking domestic market, and, unfortunately also rising social costs of caring for the elderly.
Some might expect countries with aging populations to experience declines in growth and economic output, which can happen to some extent, but data from the Harvard Growth Lab suggests that economic development also requires the accumulation of sophisticated productive knowledge that allows participation in more complex industries. They measure this in a metric they call the Economic Complexity Index (ECI). Thus, countries like Japan can minimize the negative impact of their aging population because they rank very high on the Economic Complexity Index (ECI), giving them some protection from a dwindling young labor force.
While each country has a unique demographic profile, one thing is clear, we see that as education and wealth levels rise around the world, fertility rates are falling almost everywhere. The benefit of having a large young population is the opportunity created when large numbers of young people enter the workforce and help accelerate the economic momentum. This is sometimes referred to as the “Demographic Dividend”.
For economic growth to occur the younger population must have access to quality education, adequate nutrition, and health and be able to find gainful employment. Events of the past decade, ranging from the Arab uprisings to the more recent mass protests in Chile and Sudan, also show that countries that fail to generate sufficient jobs for large cohorts of young adults of working age are prone to social, political, and economic instability. The “demographic dividend” refers to the process through which a changing age structure can boost economic growth but this depends on several complex supporting factors that can be difficult to orchestrate. Thus, while the overall outlook for Africa is very positive, the demographic dividend can only materialize if these supporting social, economic policy, and educational investment factors are aligned, and this may not happen uniformly across Africa.
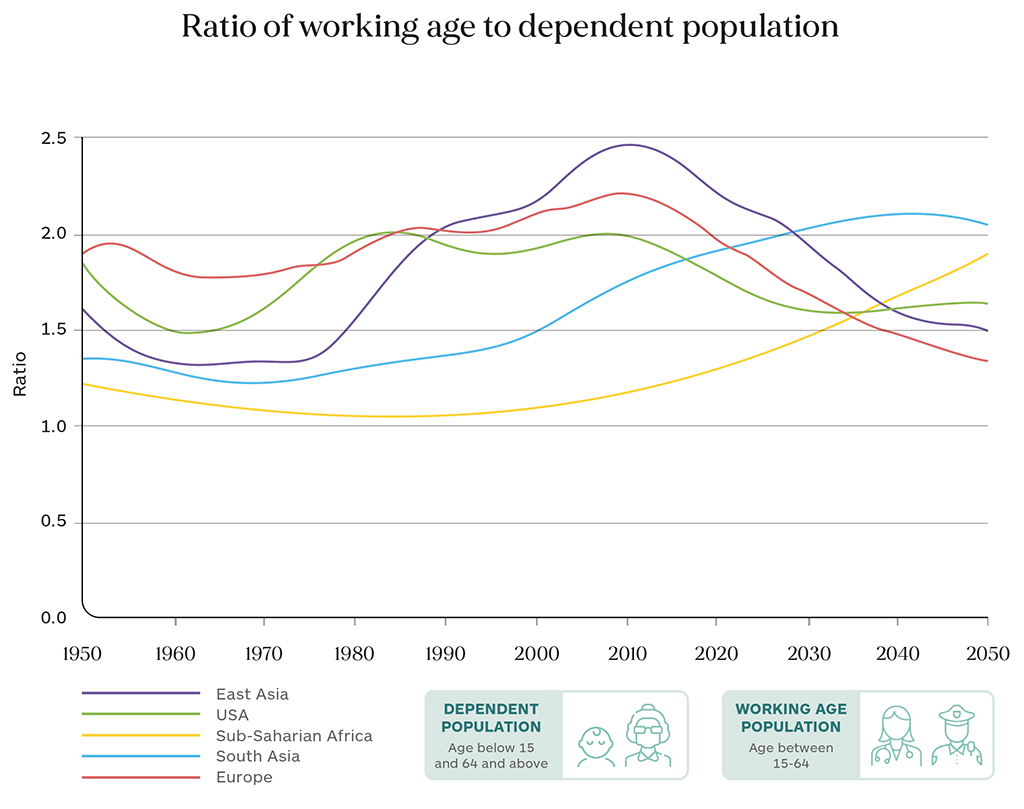
To understand the potential demographic impact on economic dynamism, it is also useful to also look at the ratio of the working-age population to the dependent population (under 15 and over 65). This measures the economic pressure on those of working age to support those who are not of working age. The trends suggest that in the coming decades, demographics will be more favorable to increasing economic prosperity in less developed regions than in more developed regions. The chart below shows the Inverse dependency ratios in world regions, showing the demographic window of opportunity when the proportion of the working population is most pronounced, an economic boom period that typically lasts 40-50 years. A baby boom typically precedes the economic boom and the chart shows the demographic window for the US (1970–2030) and East Asia (1980–2040), when a large cohort of young workers entered the labor force to accelerate economic momentum. South Asia has just entered its demographic window phase and much of Africa is probably still 10 years away from entering this phase. It also appears that both Europe and East Asia will enter a more challenging demographic transition from 2030 onwards as they grapple with an increasing population graying.
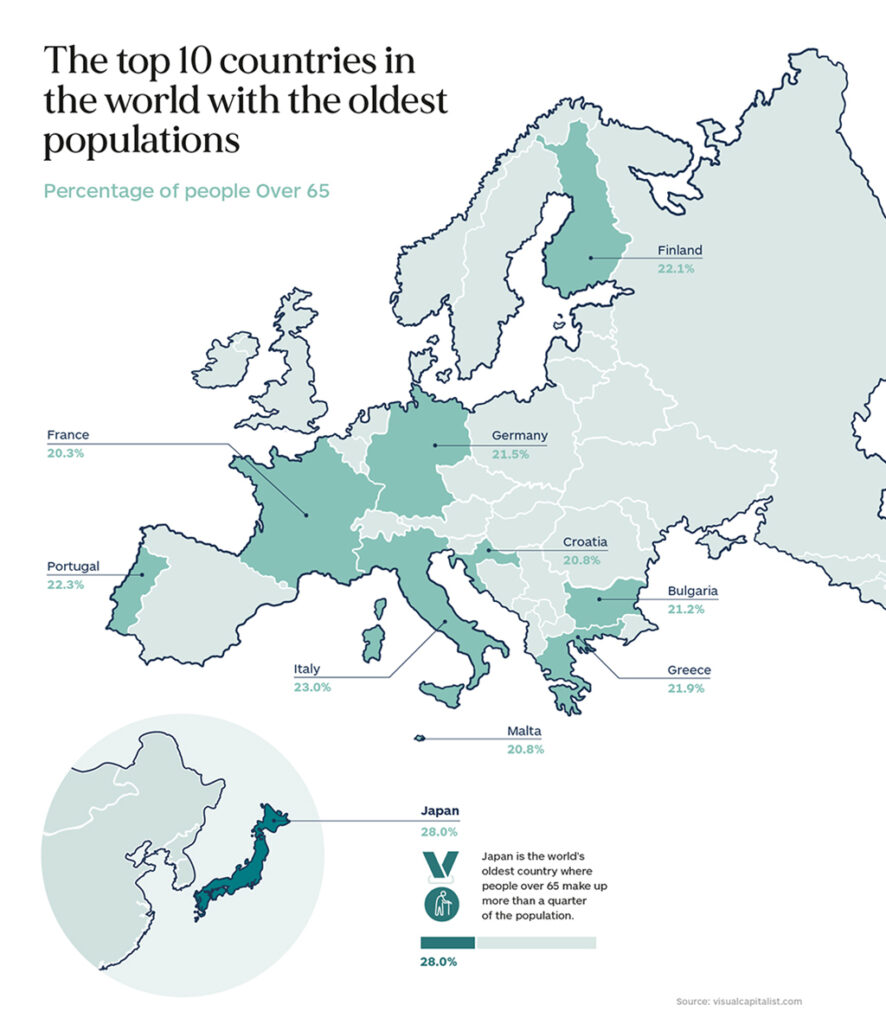
Population aging is the dominant demographic trend of the 21st century—a reflection of increasing longevity, declining fertility, and the transition of large cohorts to older ages. In fact, aging is a cause for alarm all over the world. Over the next three decades, nearly 2 billion+ people are expected to be 65 or older, with more and more moving into the 85+ range. The impact of this growing gray cohort is difficult to predict as humanity has not experienced this situation in recorded history.
Thus, while demographics can have a significant impact on the emerging future, purely demographic trends need to be balanced with an indicator of economic strength that reflects the diversity and complex productive capabilities (Economic Complexity Index – ECI) of different nations. The Harvard Growth Lab predicts that China, Vietnam, Uganda, Indonesia, and India will be among the fastest-growing economies over the coming decade.
The Harvard Growth Labs identify three poles of growth. Several Asian economies already have the economic complexity to drive the fastest growth over the next decade, led by China, Cambodia, Vietnam, Indonesia, Malaysia, and India. In East Africa, several economies are expected to experience rapid growth, though this will be driven more by population growth than gains in economic complexity, including Uganda, Tanzania, and Mozambique. On a per capita basis, Eastern Europe has strong growth potential for its continued progress in economic complexity, with Georgia, Lithuania, Belarus, Armenia, Latvia, Bosnia, Romania, and Albania all ranking among the projected top 15 economies on a per capita basis. Outside these growth poles, the projections also show more rapid growth potential for Egypt. Other developing regions, such as Latin America and the Caribbean, and West Africa, face more challenging growth prospects because they have made fewer gains in economic complexity. All of these factors have implications for which languages will be most important as machine translation technology evolves. While some languages will be important for commerce, others will be important for education and social welfare impact.
The Challenge of Building Low Resource Language MT Systems
While computational costs continue to fall and algorithms are becoming increasingly commoditized, the outlook on the data front is much more challenging. Years of experience working with existing NMT models show that the best models are those with the largest amount of relevant bilingual training data. There are probably at least 20 language combinations, and perhaps as many as 50, that have enough training data to build robust generic MT engines that meet the needs of a wide variety of use cases at acceptable performance levels.
For the vast majority of these “better” MT systems, English is likely to be one of the languages in the combination. However, for the vast majority of languages, there is not enough bilingual data to train and build good NMT systems. Thus, today we have a situation where the MT experience of a French speaker is likely to be much more compelling and useful than the experience of a Hausa speaker. The chart below explains the main reason for the less satisfactory experience with low-resource languages. There is simply not enough data to properly train and build robust MT systems for language combinations that lack bilingual training data. The languages for which relatively small amounts of bilingual data are available are referred to as “low-resource” languages.
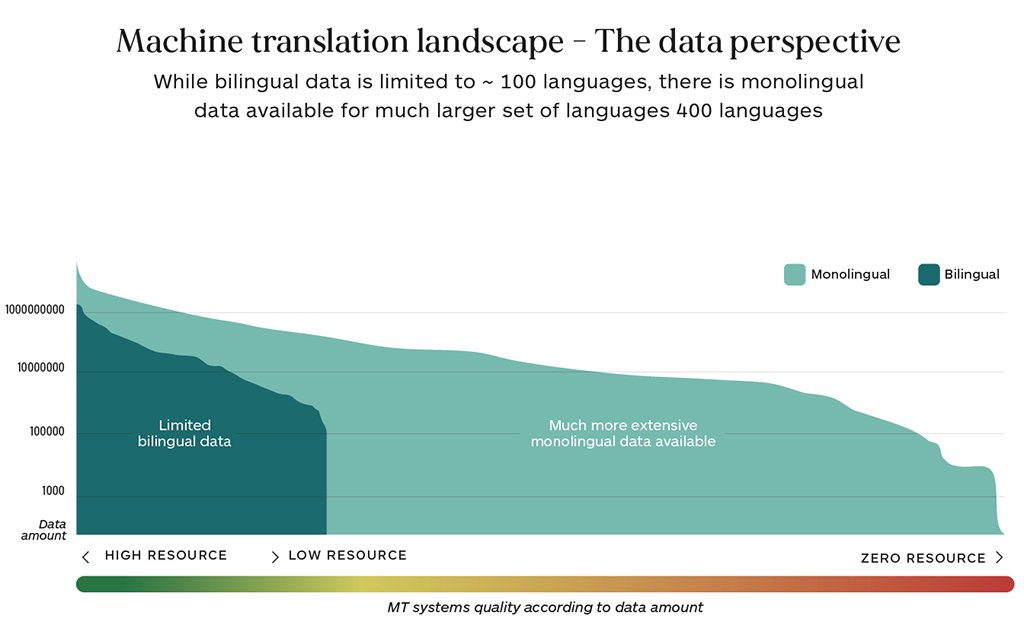
As the focus on low-resource languages grows, driven by the need to engage the millions of new Internet users who mostly come from low-resource or even zero-resource language areas, there are several technological initiatives underway to address the problem of making usable machine translation available for more languages. While it is also possible to also have concerted human-driven efforts to collect the critical data, the volume of data required makes this a much more difficult path.
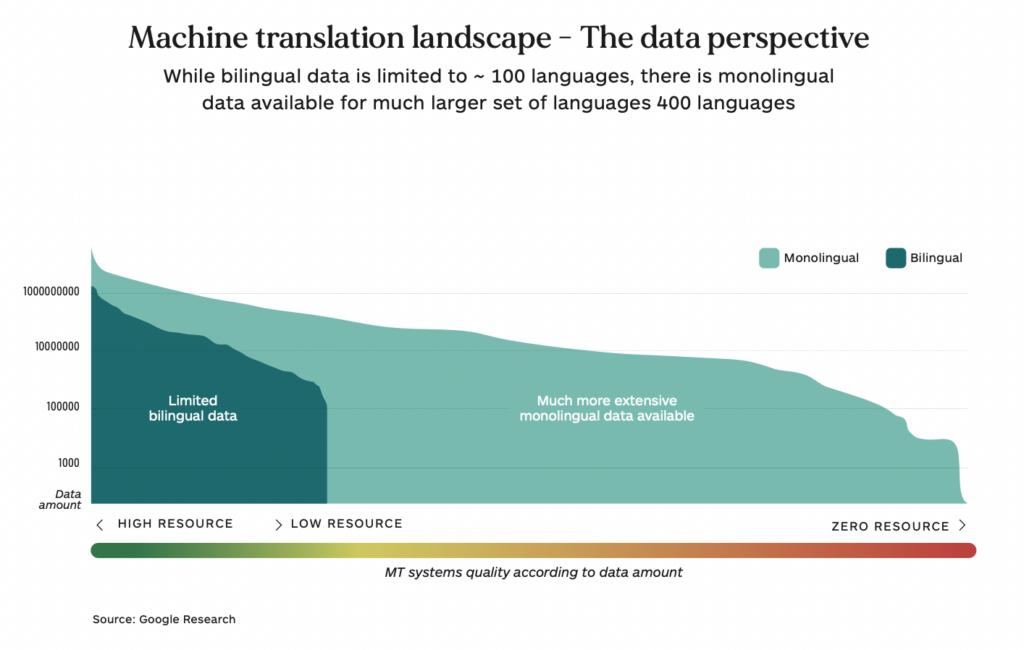
Essentially, there are three approaches to solving the data scarcity problem for low-resource languages:
- Human-driven data collection can only occur at a meaningful scale if there is a coordinated effort from the government, academia, the scientific community, and the general public. Humanitarian initiatives such as Clear Global and Translation Commons (UNESCO) can also contribute small amounts of data around key focus areas such as refugee, health, and natural disaster relief scenarios.
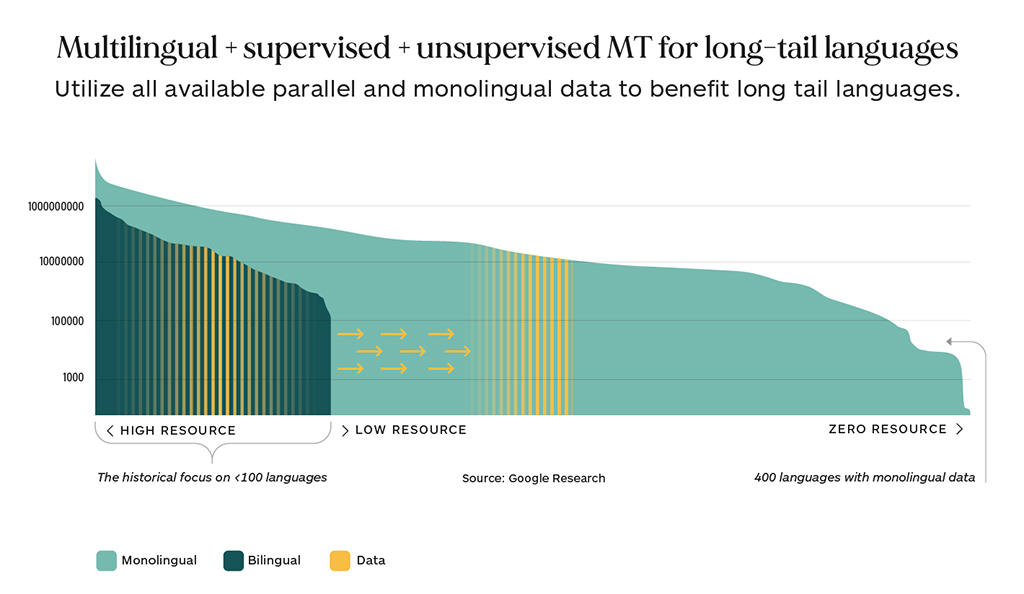
- Massively multilingual MT approaches where large groups of language pairs (10-200) are trained together. This allows the use of data from high-resource language pairs to be used to improve the quality of low-resource languages. While this does not always benefit the performance of the high-resource languages there is clear evidence that it does benefit the low-resource languages.
- Use more readily available monolingual data to supplement limited amounts of bilingual data. This strategy could enable the development of MT systems for the long tail of languages.
Human-Driven Data Collection: While it is very difficult to scale this approach to create the critical mass of data, it can be the means to acquire the highest quality data. Humanitarian initiatives collect data around key events, such as the Rohingya refugee crisis or health worker support for multiple regional languages in the Democratic Republic of the Congo. The following is a summary of possible actions that could be taken for an organized data collection effort.
Massively Multilingual MT:Multilingual Supervised NMT uses data from high-resource language pairs to improve the quality of low-resource languages and simplifies deployment by requiring only a single model. Meta reported that their NLLB (200-Language – No Language Left Behind) model which is an attempt to develop a general-purpose universal machine translation model capable of translating between any two languages in different domains, outperformed even many of their bilingual models. This approach is very costly in terms of computation costs and therefore can only seriously be considered by Big Tech. However, Meta has made the data, models, and codebase available to the larger MT community to encourage research and refinement of the technology and invites collaboration from a broad range of stakeholders including translators. This is an important acknowledgment that competent human feedback is a key input to continuous improvement.
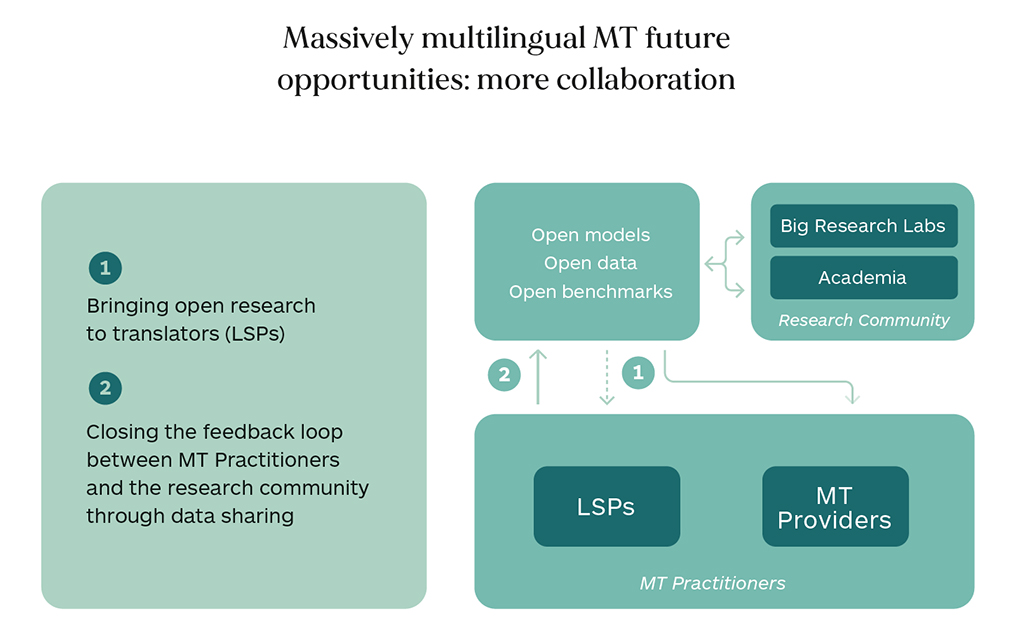
Increased Use of Monolingual Data: As monolingual data is more easily available, and it is easier to acquire in larger quantities, it is expected that this will be an area where more progress can be made in future research. In recent years, there has been some progress on unsupervised approaches that can directly use monolingual data directly to learn machine translation for a new language. New research is underway to identify new ways to maximize the use of monolingual data when bilingual data is scarce.
The capabilities of MT have varied across language combinations, with the best performance (BLEU scores) historically coming from data-rich high-resource languages. This could change as new techniques are applied and multilingual MT technology matures. As more speakers of low-resource languages realize the benefits of broad access across knowledge domains that good MT allows, some of these languages may evolve and improve more rapidly with active and engaged communities providing valuable corrective feedback. Consistently improving MT in a growing number of languages can only help to improve the global dialogue.
It is also expected that as more emerging markets begin to actively use MT, the technology will increasingly be used on mobile platforms. It is also likely that speech-to-speech (STS) translation capabilities will grow in importance. These new systems will be much more powerful than the tourism-oriented STS systems that we see today.
However, expectations of MT for professional use are much more demanding, as the performance requirement is often to be as close as possible to human equivalence. Well-regarded generic MT (with high BLEU scores) can slow down or otherwise hinder professional translation production workflows. Rapidly improving adaptive MT systems is a critical requirement in professional use to ensure continuous productivity improvements and ensure high ROI.
Translated SRL has recently provided the most compelling evidence to date of the continuous quality improvements in MT over time, especially when used in a professional translation production scenario. Measurements taken over several years by monitoring the behavior of over 100,000 expert translators, correcting 2 billion sentence segments, and covering many domains across six languages, show the relentless progress being made with MT in the professional use case. This progress is highly dependent on the specialized, responsive, and highly adaptive underlying ModernMT technology which automates the collection of corrective feedback and rapidly incorporates this new learning into a flexible and continuously improving MT system.
This formalization of an active and collaborative relationship between humans and machines seems to be an increasingly important modus operandi for improving not only MT but any AI.
While AI can dramatically scale many types of cognitive tasks and, in most cases produce useful output, there are also risks. Because much of the “knowledge” in machine learning is extracted from massive volumes of training data, there is always the risk that bad, noisy, biased, or just plain wrong data will drive the model’s behavior and output. This is evident in the news cycle we see with several Large Language Model (LLM) initiatives such as LaMDA, Galactica, and ChatGPT. The initial excitement with what appears to be eerily fluent human-like output tends to subside as more erratic, hallucinatory, and even dangerous output is unearthed, followed by an increasing awareness that oversight and control are needed in any industrial application of this technology. Putting guardrails around the problem is not enough. Increasing the volume of training data, the strategy used so far, will not solve this problem. The same structural problems plague all large language models. Although GPT-4 will appear smarter than its predecessors, its internal architecture remains problematic. What we will see is a familiar pattern: immense initial excitement, followed by more careful scientific scrutiny, followed by the realization that many problems remain and that it should be used with caution and human oversight, and supervision.
The well-engineered human-in-the-loop process that can provide rapidly assimilated and learned corrective feedback, from experts, will be an increasingly more important element of any truly useful AI initiative in the future. And to return to our MT discussion we should also understand that technology is a means to scale information sharing and enable smoother, and faster communication but that this capability is not the heart of the matter.
To solve big problems, we need shared goals and a common purpose. Shared purpose, common goals, and human connection are better foundations for successful collaboration than technology and tools alone. Human connection is always more important in building robust and sustained collaboration, and we have yet to find the means to embed this sensibility in the machine.
The future of AI is to be a superlative assistant in an increasing range of cognitive tasks, while continuously learning to improve and become more accurate with each contribution. This kind of AI assistant is likely to be invaluable as humans learn to work together to solve the biggest problems that we face.

Kirti Vashee
Language technology evangelist at Translated
Kirti Vashee is a Language Technology Evangelist at Translated Srl, and was previously an Independent Consultant focusing on MT and Translation Technology. Kirti has been involved with MT for almost 20 years, starting with the pioneering use of Statistical MT in the early 2000s. He was formerly associated with several MT developers including Language Weaver, RWS/SDL, Systran, and Asia Online. He has long-term experience in the MT technology arena and prior to that worked for several software companies including, Lotus, Legato, & EMC. He is the moderator of the "Inner Circle" Automated Language Translation (MT) group with almost 11,000 members in LinkedIn, and also a former board member of AMTA (American Machine Translation Association). He is active on Twitter (@kvashee) and is the Editor and Chief Contributor to a respected blog that focuses on MT, AI and Translation Automation and Industry related issues.
Photo credit: Shubham Dhage, Unsplash