
Technology
Introduction
We see today that machine learning applications around natural language data are in full swing. In 2021 NLP oriented research announced breakthroughs in multiple areas, but especially around improving NMT systems and NLG (natural language generating) systems like the Generative Pre-trained Transformer 3 (GPT-3), which can produce digital text that appears to be human though not consistently so. Basically, it predicts the next word given a text history, and often the generated text is relevant and useful.
GPT-3 and other large language models (LLMs) can generate algorithm-written text that has the potential to be practically indistinguishable from human-written sentences, paragraphs, articles, short stories, dialogue, lyrics, and more. This suggests that these systems could be useful in many text-heavy applications in business and possibly enhance enterprise-to-customer interactions involving textual information in various forms.
The hype and excitement around GPT-3 have triggered multiple initiatives across the world, and we see today that the massive corpus of 175 billion parameters used in building GPT-3 has already been overshadowed by several other models that are even larger, e.g. Gopher from Deepmind has been built with 280 billion parameters and claims better performance in most benchmark tests used to evaluate the capabilities of these models.
The hype around some of these “breakthrough” capabilities inevitably raises questions about the increasing role of Language AI capabilities in a growing range of knowledge work. Are we likely to see an increased presence of machines in human language-related work? Is there a possibility that machines can replace humans in a growing range of language-related work?
A current trend in LLMs development is to design ever-larger models in an attempt to reach new heights but no company has rigorously analyzed which variables affect the power of these models. But many critics are saying that larger models are unlikely to solve the problems that have been identified, namely, the absence of comprehension and common sense.

oXXIgen
Imminent Research Report 2022
GET INSPIRED with articles, research reports and country insights – created by our multicultural interdisciplinary community of experts with the common desire to look to the future.
Get your copy nowThe initial euphoria is giving way to an awareness of the problems that are also inherent in LLMs and an understanding that adding more data and more computing cannot and will not solve the toxicity and bias problems that have been uncovered. Critics are saying that scale does not seem to help much when it comes to “understanding” and building GPT-4 with a 100 trillion parameters, at huge expense, may not help at all. The toxicity and bias inherent in these systems will not be easily overcome without strategies that involve more than simply adding more data and applying more computing cycles. However, what these strategies are, is not yet clear though many say this will require looking beyond machine learning.
GPT-3 and other LLMs can be fooled into creating incorrect, racist, sexist, and biased content that’s devoid of common sense and real-world sensibility. The model’s output is dependent on its input: garbage in, garbage out.
If you dig deeper, you discover that something’s amiss: although its output is grammatical, and even impressively idiomatic, its comprehension of the world is often seriously off, which means you can never really trust what it says. Unreliable AI that is pervasive and ubiquitous is a potential creator of societal problems on a grand scale.
Despite the occasional ability to produce human-like outputs, ML algorithms are at their core only complex mathematical functions that map observations to outcomes. They can forecast patterns that they have previously seen and explicitly learned from. Therefore, they’re only as good as the data they train on and start to break down as real-world data starts to deviate from examples seen during training.
In December 2021 an incident with Amazon Alexa exposed the problem that language AI products have. Alexa told a child to essentially electrocute herself (touch a live electrical plug with a penny) as part of a challenge game. This incident and many others with LLMs show that these algorithms lack comprehension and common sense, and can make non-sensical suggestions that could be dangerous or even life-threatening. “No current AI is remotely close to understanding the everyday physical or psychological world, what we have now is an approximation to intelligence, not the real thing, and as such it will never really be trustworthy,” said Gary Marcus in response to this incident.
Large pre-trained statistical models can do almost anything, at least enough for a proof of concept, but there is little that they can do reliably—precisely because they skirt the foundations that are required.
Thus we see an increasing acknowledgment from the AI community that language is indeed a hard problem. One that cannot necessarily be solved by using more data and algorithms alone, and other strategies will need to be employed. This does not mean that these systems cannot be useful, but we are beginning to understand that they are useful, but have to be used with care and human oversight, at least until machines have more robust comprehension and common sense.
We already see that machine translation today is ubiquitous, and by many estimates is responsible for 99.5% or more of all language translation done on the planet on any given day. But we also see that MT is used mostly to translate material that is voluminous, short-lived, transitory and that would never get translated if the machine were not available. Trillions of words a day are being translated by MT daily, yet when it matters, there is always human oversight on translations tasks that may have a high impact or when there is a greater potential risk or liability from mistranslation.
While machine learning use-cases continue to expand dramatically, there is also an increasing awareness that a human-in-the-loop is often necessary since the machine lacks comprehension, cognition, and common sense.
As Rodney Brooks, the co-founder of iRobot said in a post entitled – An Inconvenient Truth About AI: “Just about every successful deployment of AI has either one of two expedients: It has a person somewhere in the loop, or the cost of failure, should the system blunder, is very low.“
What is it about human language that makes it such a challenge for machine learning?
Members from the Singularity community summarized the problem quite neatly. They admit that “language is hard” when they explain why AI has not mastered translation yet. Machines perform best in solving problems that have binary outcomes. Michael Housman, a faculty member of Singularity University, explained that the ideal scenario for machine learning and artificial intelligence is something with fixed rules and a clear-cut measure of success or failure. He named chess as an obvious example and noted machines were able to beat the best human Go player. This happened faster than anyone anticipated because of the game’s very clear rules and limited set of moves. Machine learning works best when there is one or a defined and limited set of correct answers.
Housman elaborated, “Language is almost the opposite of that. There aren’t as clearly-cut and defined rules. The conversation can go in an infinite number of different directions. And then, of course, you need labeled data. You need to tell the machine to do it right or wrong.”
Housman noted that it’s inherently difficult to assign these informative labels. “Two translators won’t even agree on whether it was translated properly or not,” he said. “Language is kind of the wild west, in terms of data.”
Another issue is that language is surrounded by layers of situational and life context, intent, emotion, and feeling and the machine simply cannot extract all these elements from the words contained in a sentence or even by looking at millions of sentences. Exactly the same sequence of words could have multiple different semantic implications. What lies between the words is what provides the more complete semantic perspective and this is learning that machines cannot extract from a sentence. The proper training data to solve language simply does not exist and will likely never exist.
Concerning GPT-3 and other LLMs: The trouble is that you have no way of knowing in advance which formulations will or won’t give you the right answer. GPT’s fundamental flaws remain. Its performance is unreliable, causal understanding is shaky, and incoherence is a constant companion.
Hopefully, we are now beginning to understand that adding more data does not solve the problem. More data makes for a better, more fluent approximation to language; it does not make for trustworthy intelligence.
The claim to these systems being early representations of machine sentience or AGI is particularly problematic, and some critics are quite vocal in their criticism of these over-reaching pronouncements.
Summers-Stay said this about GPT-3: “GPT is odd because it doesn’t ‘care’ about getting the right answer to a question you put to it. It’s more like an improv actor who is totally dedicated to their craft, never breaks character, and has never left home but only read about the world in books. Like such an actor, when it doesn’t know something, it will just fake it. You wouldn’t trust an improv actor playing a doctor to give you medical advice.“
Ian P. McCarthy said “A liar is someone who is interested in the truth, knows it, and deliberately misrepresents it. In contrast, a bullshitter has no concern for the truth and does not know or care what is true or is not.” Gary Marcus and Ernest Davis characterize GPT-3 as “a fluent spouter of bullshit” that even with all its data is not a reliable interpreter of the world.
For example, Alberto Romero says: “The truth is these systems aren’t masters of language. They’re nothing more than mindless “stochastic parrots.” They don’t understand a thing about what they say and that makes them dangerous. They tend to “amplify biases and other issues in the training data” and regurgitate what they’ve read before, but that doesn’t stop people from ascribing intentionality to their outputs. GPT-3 should be recognized for what it is; a dumb — even if potent — language generator, and not as a machine so close to us in humanness as to call it “self-aware.”

The most compelling explanation that I have seen on why language is hard for machine learning is by Walid Saba, Founder of Ontologik.Ai. He points out that Kenneth Church, a pioneer in the use of empirical methods in NLP i.e. using data-driven, corpus-based, statistical, and machine learning (ML) methods was only interested in solving simple language tasks – the motivation was never to suggest that this technique could unravel how language works, but that “it is better to do something simple than nothing at all”. However, subsequent generations misunderstood this empirical approach which was only intended to find practical solutions to simple tasks, to be a paradigm that will scale into full natural language understanding (NLU).
This has led to widespread interest in the development of LLMs and what he calls “a futile attempt at trying to approximate the infinite object we call natural language by trying to memorize massive amounts of data.” While he sees some value for data-driven ML approaches for some NLP tasks (summarization, topic extraction, search, clustering, NER) he sees this approach as irrelevant for NLU (Natural Language Understanding) where understanding requires a much more specific and accurate understanding of the one and only one thought that a speaker is trying to convey. Machine Learning works on the specified NLP tasks above because they are consistent with the Probably Approximately Correct (PAC) paradigm that underlies all machine learning approaches, but he insists that this is not the right approach for “understanding” and NLU.
There are three reasons he explains why NLU is so difficult for Machine Learning:
1. The Missing Text Phenomenon (MTP): is believed to be at the heart of all challenges in NLU.
In human communication, an utterance by a speaker has to be decoded to get to the specific meaning intended, by the listener, for understanding to occur. There is often a reliance on common background knowledge so that communication utterances do not have to spell out all the context. That is, for effective communication, we do not say what we can assume we all know! This genius optimization process that humans have developed over 200,000 years of evolution works quite well, precisely because we all know what we all know. But this is where the problem is in NLU: machines don’t know what we leave out, because they don’t know what we all know. The net result? NLU is very very difficult because a software program cannot fully understand the thoughts behind our linguistic utterances if they cannot somehow “uncover” all that stuff that humans leave out and implicitly assume in their linguistic communication.
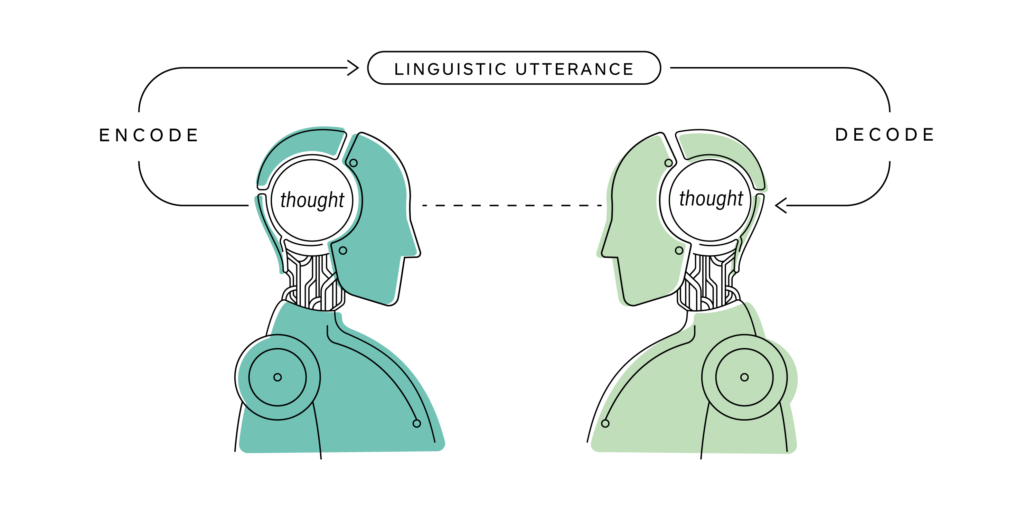
Fig. 1. Linguistic communication of thoughts by speaker and listener.
2. ML Approaches are not even relevant to NLU: ML is Compression, Language Understanding Requires Uncompressing.
Our ordinary spoken language in everyday discourse is highly (if not optimally) compressed, and thus the challenge in “understanding” is in uncompressing (or uncovering) the missing text – while for us humans that was a genius invention for effective communication, language understanding by machines is difficult because machines do not know what we all know. Even in human communications, faulty uncompressing can lead to misunderstanding. Machines do not have the visual, spatial, physical, societal, cultural, and historical context, all of which remain in the common understanding but unstated zone to enable understanding. This is also true to a lesser extent for written communication.
What the above says is the following: machine learning is about discovering a generalization of lots of data into a single function. Natural language understanding, on the other hand, and due to MTP, requires intelligent ‘uncompressing’ techniques that would uncover all the missing and implicitly assumed text. Thus, he claims machine learning and language understanding are incompatible and are contradictory.
3. Statistical Insignificance: ML is essentially a paradigm that is based on finding some patterns (correlations) in the data.
Thus, the hope in that paradigm is that there are statistically significant differences to capture the various phenomena in natural language. Using larger data sets assumes that ML will capture all the variations. However, renowned cognitive scientist George Miller said: To capture all syntactic and semantic variations that an NLU system would require, the number of features a neural network might need is more than the number of atoms in the universe! The moral here is this: statistics cannot capture (nor even approximate) semantics.
Pragmatics is the branch of linguistics that studies how context contributes to meaning. George Herbert Mead, an important pragmatist of the 19th century, argued that communication is more than the words we use; “it involves the all-important social signs people make when they communicate.” Now, how could an AI system access contextual information? The key issue is that ML systems are fed words (the tip of the iceberg) and these words don’t contain the necessary pragmatic information. Humans infer it from them. Pragmatics lives in the common knowledge people share about how the world works. People can express more than words can convey because we live in a shared reality. But AI algorithms don’t share that reality with us.
Philosopher Hubert Dreyfus, one of the 20th century leading critics, argued against current approaches to AI saying that most of the human expertise comes in the form of tacit knowledge — experiential and intuitive knowledge that can’t be directly transmitted or codified and is thus inaccessible to machine learning. Language expertise is no different, and it’s precisely the pragmatic dimension that is often intertwined with tacit knowledge.
oXXIgen
Imminent Research Report 2022
GET INSPIRED with articles, research reports and country insights – created by our multicultural interdisciplinary community of experts with the common desire to look to the future.
Get your copy nowTo summarize: in conveying our thoughts we transmit highly compressed linguistic utterances that need a mind to interpret and ‘uncover’ all the background information that was missing but implicitly assumed. This dynamic uncompression action which is multi-modal and multi-contextual is what leads to “understanding”.
Languages are the external artifacts that we use to encode the infinite number of thoughts that we might have. In so many ways, then, in building larger and larger language models, Machine Learning and Data-Driven approaches are trying to chase infinity in a futile attempt at trying to find something that is not even ‘there’ in the data.
Another criticism focuses more on the “general intelligence” claims being made about AI by people like OpenAI. Each of our AI techniques manages to replicate some aspects of what we know about human intelligence. But putting it all together and filling the gaps remains a major challenge. In his book Algorithms Are Not Enough, data scientist Herbert Roitblat provides an in-depth review of different branches of AI and describes why each of them falls short of the dream of creating general intelligence.
The common shortcoming across all AI algorithms is the need for predefined representations, Roitblat asserts. Once we discover a problem and can represent it in a computable way, we can create AI algorithms that can solve it, often more efficiently than ourselves. It is, however, the undiscovered and unrepresentable problems that continue to elude us. There are always problems outside the known set and thus there are problems that models cannot solve.
“These language models are significant achievements, but they are not general intelligence,” Roitblat says. “Essentially, they model the sequence of words in a language. They are plagiarists with a layer of abstraction. Give it a prompt and it will create a text that has the statistical properties of the pages it has read, but no relation to anything other than the language. It solves a specific problem, like all current artificial intelligence applications. It is just what it is advertised to be — a language model. That’s not nothing, but it is not general intelligence.”
“Intelligent people can recognize the existence of a problem, define its nature, and represent it,” Roitblat writes. “They can recognize where knowledge is lacking and work to obtain that knowledge. Although intelligent people benefit from structured instructions, they are also capable of seeking out their own sources of information.” In a sense, humans are optimized to solve unseen and new problems by acquiring and building the knowledge base needed to address these new problems.
The path forward
Machine learning is being deployed across a wide range of industries and is successfully solving many narrowly focused problems creating substantial economic value when it is properly implemented and with relevant data. We should expect that this trend will only build more momentum.
Some experts say that we are only at the beginning of a major value creation cycle driven by machine learning that will have an impact as deep and as widespread as the development of the Internet itself. The future giants of the world economy are likely to be companies that have comprehensive and leading-edge ML capabilities.
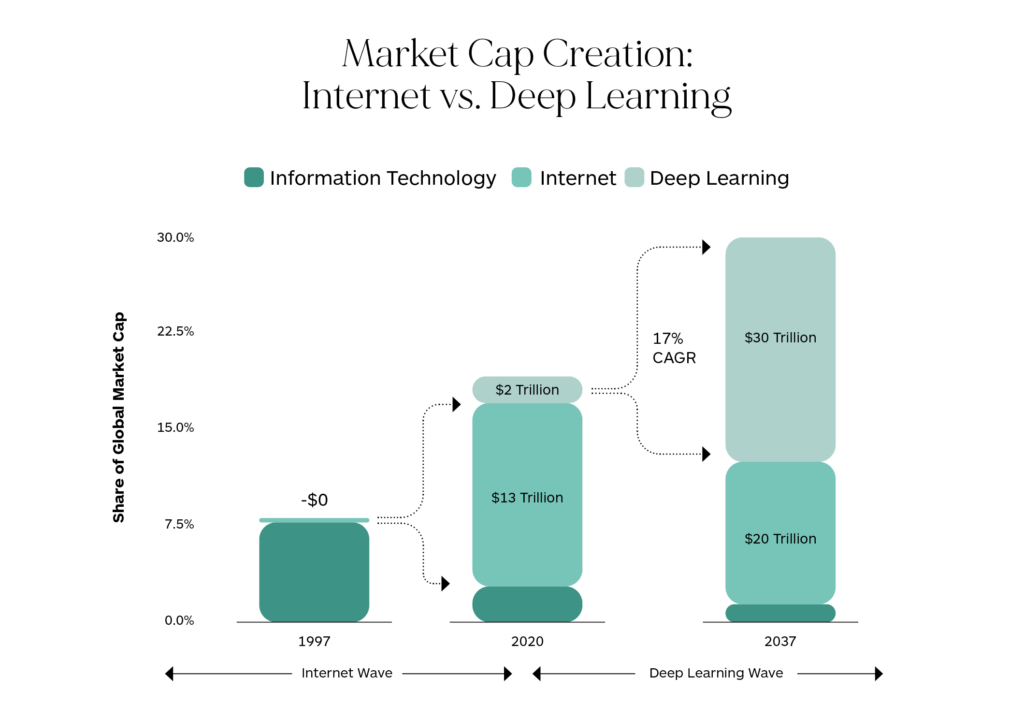
Fig. 2: Deep learning to create $30T in market cap value by 2037? (Source: ARK Invest).
However, we also know that AI lacks a theory of mind, common sense and causal reasoning, extrapolation capabilities, and a body, and so it is still extremely far from being “better than us” at almost anything slightly complex or general. These are challenges that are not easily solved by deep learning approaches. New thinking will be needed and we will need to move on from the more data plus more computing approach to solve all our AI related problems.
“The great irony of common sense—and indeed AI itself—is that it is stuff that pretty much everybody knows, yet nobody seems to know what exactly it is or how to build machines that possess it,” said Gary Marcus, CEO, and founder of Robust.AI. “Solving this problem is, we would argue, the single most important step towards taking AI to the next level. Common sense is a critical component to building AIs that can understand what they read; that can control robots that can operate usefully and safely in the human environment; that can interact with human users in reasonable ways. Common sense is not just the hardest problem for AI; in the long run, it’s also the most important problem.”
Common sense has been called the “dark matter of AI” — both essential and frustratingly elusive. That’s because common sense consists of implicit information — the broad (and broadly shared) set of unwritten assumptions and rules of thumb that humans automatically use to make sense of the world. Critics of over-exuberant AI claims frequently point out that two-year children have more common sense than existing deep-learning-based AI systems whose “understanding” is often quite brittle and easily distracted and deranged.
Common sense is easier to detect than to define. The implicit nature of most common-sense knowledge makes it difficult and tedious to represent explicitly.
Gary Marcus suggests combining traditional AI approaches with deep learning as a way forward.
“First, classical AI actually is a framework for building cognitive models of the world that you can then make inferences over. The second thing is, classical AI is perfectly comfortable with rules. It’s a strange sociology right now in deep learning where people want to avoid rules. They want to do everything with neural networks, and do nothing with anything that looks like classical programming. But there are problems that are routinely solved this way that nobody pays attention to, like making your route on Google maps.
We actually need both approaches. The machine-learning stuff is pretty good at learning from data, but it’s very poor at representing the kind of abstraction that computer programs represent. Classical AI is pretty good at abstraction, but it all has to be hand-coded, and there is too much knowledge in the world to manually input everything. So it seems evident that what we want is some kind of synthesis that blends these approaches.”
Thus, when we consider the goal of understanding and wanting to be understood, we must admit that this is very likely always going to require a human-in-the-loop, even when we get to building deep learning models that are built with trillions of words. The most meaningful progress will be related to the value and extent of the assistive role that Language AI will play in enhancing our ability to communicate, share, and digest knowledge.
Human-in-the-loop (HITL), is the process of leveraging the power of the machine and enabling high-value human intelligence interactions to create continuously improving machine learning-based AI models. Active learning generally refers to the humans handling low confidence units and feeding improvements back into the model. Human-in-the-loop is broader, encompassing active learning approaches as well as the creation of data sets through human labeling.
HITL describes the process when the machine is unable to solve a problem based on initial training data alone and needs human intervention to improve both the training and testing stages of building an algorithm. Properly done, this creates an active feedback loop allowing the algorithm to give continuously better results with ongoing use and feedback.
With language translation, the critical training data is translation memory.
However, the truth is that there is no existing training data set (TM) that is so perfect, complete, and comprehensive as to produce an algorithm that consistently produces perfect translations.
Again to quote Roitblat:
“Like much of machine intelligence, the real genius [of deep learning] comes from how the system is designed, not from any autonomous intelligence of its own. Clever representations, including clever architecture, make clever machine intelligence.”
This suggests that humans will remain at the center of complex, knowledge-based AI applications involving language even though the way humans work will continue to change. As the use of machine learning proliferates, there is an increasing awareness that humans working together with machines in an active learning contribution mode can often outperform the possibilities of machines or humans alone. The future is more likely to be about how to make AI be a useful assistant than it is about replacing humans.
Photo credits: Jackson So, Unsplash / , Unsplash / Unsplash