
Technology
- Understanding the Low-Resource Language Crisis
- Community-Centered Approaches: Lessons from LT4ALL 2025
- The Transformation Potential of AI for Language Preservation
- A Comprehensive Framework for Low-Resource Language Preservation
- Ethical Considerations and Sustainability
- Conclusion: Toward Digital Linguistic Equity
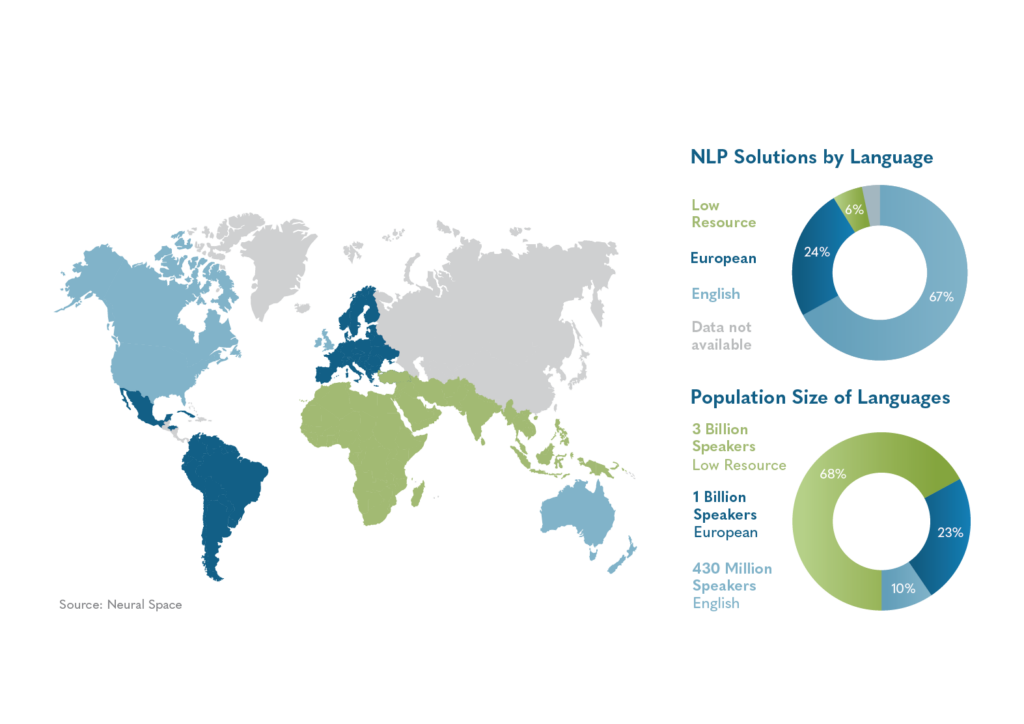
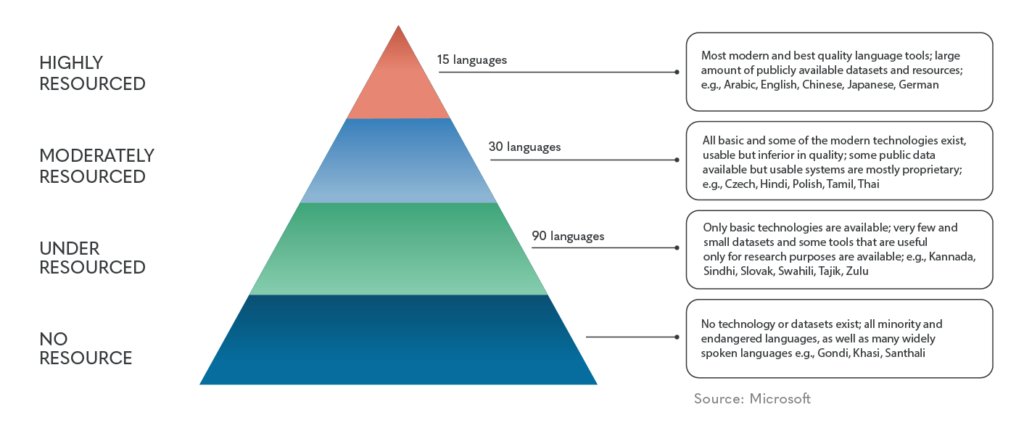
The sine qua non for developing Natural Language Processing (NLP) solutions for any language is the accessibility of linguistic data. Despite the existence of over 7,000 languages worldwide, only approximately 20 possess sizable textual corpora. Notably, English exhibits the most extensive dataset, with Chinese and Spanish following. The remaining languages featuring substantial datasets are predominantly comprised of Western European languages and Japanese.
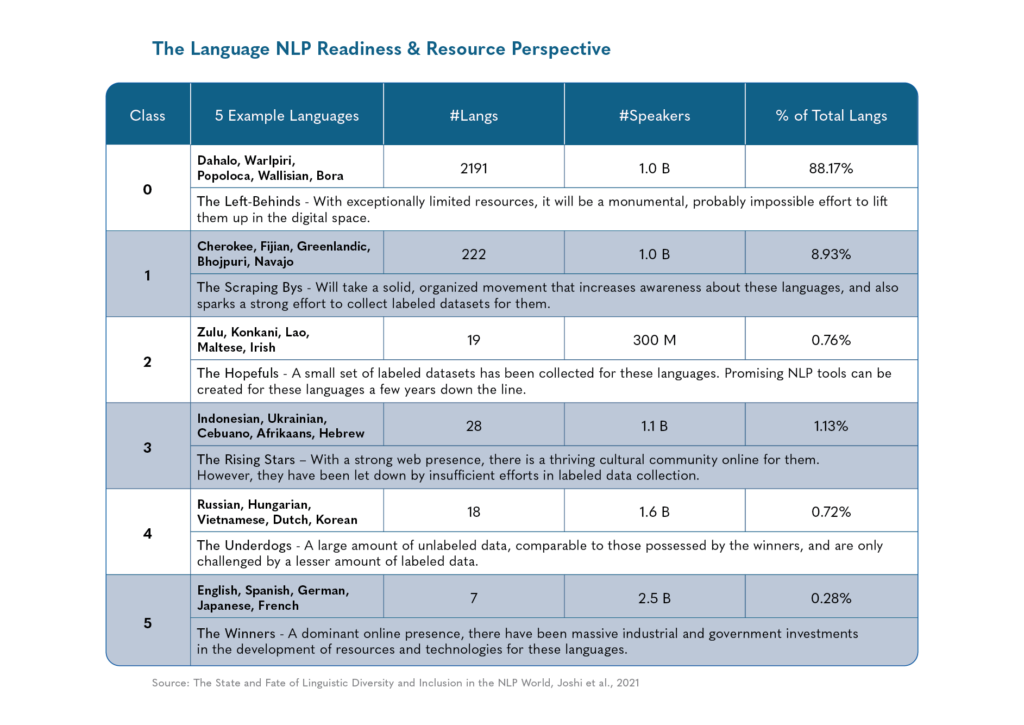
On the other hand, most of the languages spoken in Southern Asia and Africa lack the training data required to build accurate state-of-the-art NLP systems. These languages are called low-resource languages. Technically speaking, a language is considered a low-resource language when it lacks large monolingual or parallel corpora and/or manually crafted linguistic resources sufficient for building NLP applications. The recent LT4All (Language Technologies for All) 2025 conference at UNESCO Headquarters in Paris highlighted a critical truth about our global linguistic heritage: despite technological advances, thousands of languages remain at the precipice of digital extinction. The conference, themed “Advancing Humanism through Language Technologies,” brought together researchers, developers, and linguistic communities to address this growing crisis.
As we examine the outcomes of this landmark event, alongside recent technological breakthroughs, a clearer path forward emerges for addressing the low-resource language dilemma. Languages that lack sufficient digital resources represent not merely communication systems but repositories of unique cultural wisdom, traditional knowledge, and distinct worldviews that enrich our collective human experience. This article presents a comprehensive framework for leveraging artificial intelligence to preserve and revitalize these linguistic treasures, with particular attention to community-centered approaches and innovative technological solutions.
As language technologies evolve, the path forward requires harmonizing technical innovation with cultural stewardship, ensuring that preservation efforts authentically serve language communities while leveraging the latest computational methods.
Understanding the Low-Resource Language Crisis
Low-resource languages, typically spoken by smaller populations, face existential threats in our increasingly digital world. These languages lack comprehensive linguistic resources such as written documentation, digital tools, and academic research needed for computational applications. The scarcity of resources creates a vicious cycle: without sufficient data, developing effective language technologies becomes difficult; without these technologies, creating more digital content remains challenging. This dilemma accelerates language endangerment, with many indigenous and minority languages already at risk of disappearing within a generation. The scarcity of digital sources, language data, and suitable tools presents formidable difficulties for creating effective language technologies. Critical Natural Language Processing (NLP) tasks like part-of-speech tagging, machine translation, sentiment analysis, and information retrieval remain challenging for these languages.1 This digital marginalization accelerates the endangerment of these languages, with UNESCO estimating that 40% of languages globally face the risk of extinction.
The English language dominates the development of artificial intelligence (AI). Many leading language models are trained on nearly a thousand times more English text than other languages. These disparities in AI have real-world impacts, especially for racialized and marginalized communities. English-centric AI has resulted in inaccurate medical advice in Hindi,2 led to wrongful arrest because of mistranslations in Arabic,3 and has been accused of fueling violence in Ethiopia due to poor moderation of hate speech in Amharic and Tigrinya.4
The historical context behind language endangerment cannot be overlooked. Many indigenous languages face threats due to colonial legacies that imposed dominant languages through forced assimilation policies. Despite these challenges, communities have demonstrated remarkable resilience in maintaining their linguistic heritage. The LT4All 2025 conference5 explicitly acknowledged this history, framing language technology development not merely as technical innovation, but as a moral imperative for cultural preservation and linguistic justice.
The implications of this are serious and summarized below:
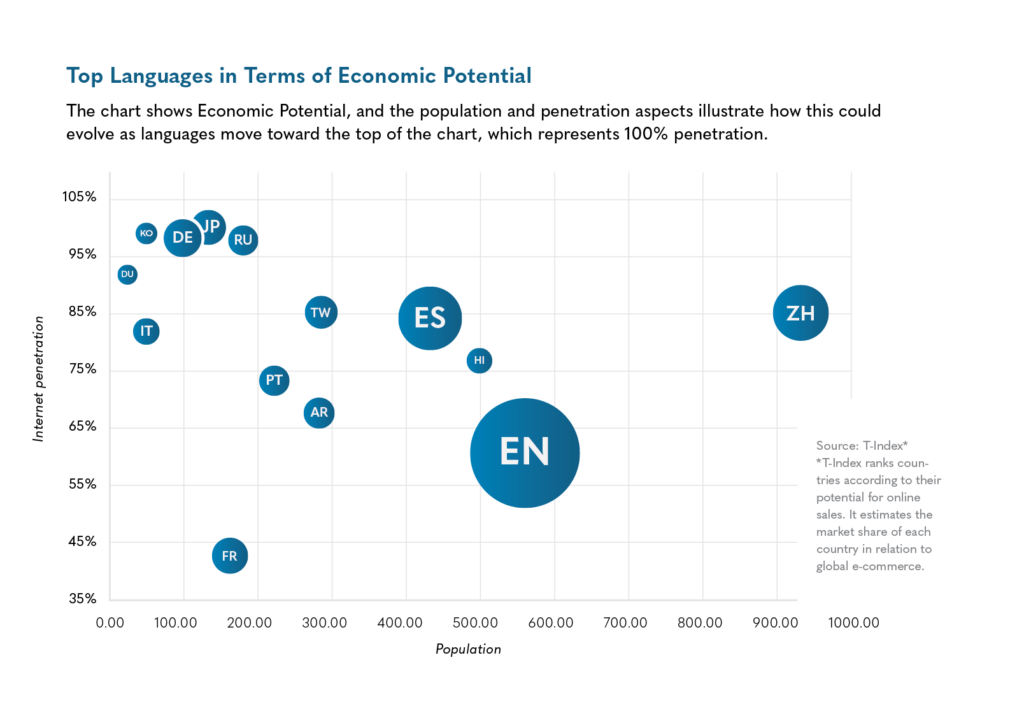
• Generative AI tends to reflect a North American, English-speaking perspective.
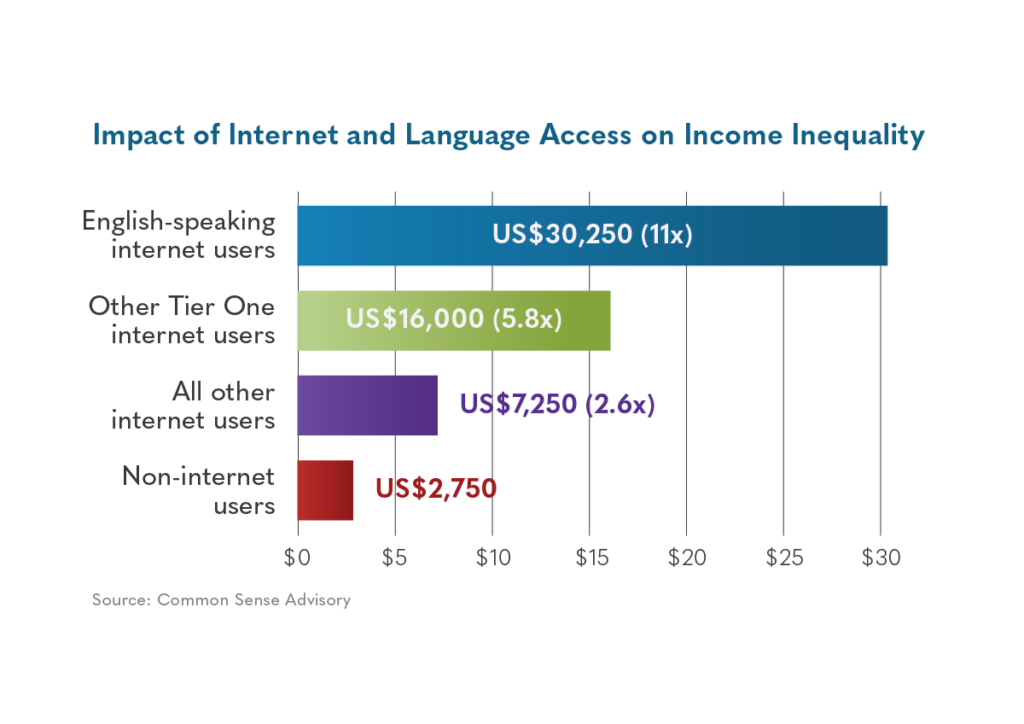
• Digital wealth disparity: 63% of the world’s population has internet access and possesses 93% of global wealth.
• The excluded 37%: 3 billion people without internet access own only 7% of global wealth.
• Worsening inequality: LLM training data is set to reinforce digital and linguistic disparities.
• Linguistic dominance: A slide showcasing CSA Research’s 17 tier-one languages, each reaching at least 1% of online wealth (eGDP).
• Economic disparities in digital access: Data analysis by CSA Research shows that 17 tier-one languages dominate the online world, and that this has significant implications on economic well-being.
Community-Centered Approaches: Lessons from LT4ALL 2025
The Transformation Potential of AI for Language Preservation Artificial intelligence offers unprecedented opportunities to address challenges faced by low-resource languages. Machine learning algorithms, particularly advanced neural networks and large language models (LLMs), can now learn from limited data in ways that were previously impossible. These technologies provide means to amplify and preserve linguistic data, creating tools to document and promote endangered languages even when resources are scarce.
The evidence strongly suggests that neither monolingual data amplification nor community engagement alone provides a complete solution. Instead, the most effective approach integrates both strategies:
1. Technical methods maximize value from available monolingual data.
2. Community partnerships ensure cultural relevance and ethical data practices.
3. Continuous feedback loops connect technical development with community needs.
This synthesis enables what several LT4ALL 2025 presenters described as “culturally anchored AI” – systems that leverage cutting-edge technology while respecting and preserving the cultural contexts embedded in language.
The Transformation Potential of AI for Language Preservation
The LT4ALL 20256 conference emphasized that technological solutions must be developed in partnership with language communities rather than imposed upon them. This principle recognizes that language preservation is not merely a technical challenge but a sociocultural process that must respect the autonomy and wisdom of language communities.
Several successful initiatives presented at the conference demonstrated the effectiveness of community-centered approaches. AI4Bharat, for example, created its IndicVoices speech dataset for 22 Indian languages by involving diverse community members across ages, genders, and professions. They specifically designed culturally relevant data collection methods, including region-specific roleplay scenarios such as conversations about Kashmiri handcrafted items or discussions about rice varieties native to Palakkad. This tailored approach ensured that the resulting language resources authentically represented different language practices, including slang and local idioms.7 The African Languages Lab (All Lab) offered another instructive example of community engagement. This youth-led collaborative is committed to documenting, digitizing, translating, and empowering African languages through advanced AI and NLP systems.8 Their approach addresses the stark reality that, despite African languages comprising nearly one-third of all languages worldwide, only a limited subset is available on translation platforms like ModernMT and Google Translate, with most being available on translation platforms like ModernMT and Google Translate, with most being “severely underrepresented” or “completely ignored” in computational linguistics.
The initial phase must focus on establishing ethical partnerships with language communities and conducting comprehensive resource assessments:
1. Identify community leaders, language experts, and potential project champions.
2. Document existing language resources (texts, recordings, dictionaries).
3. Assess digital infrastructure access and community priorities for language preservation.
4. Establish data sovereignty agreements following models presented at LT4ALL 2025 and other low-resource and indigenous language conferences.
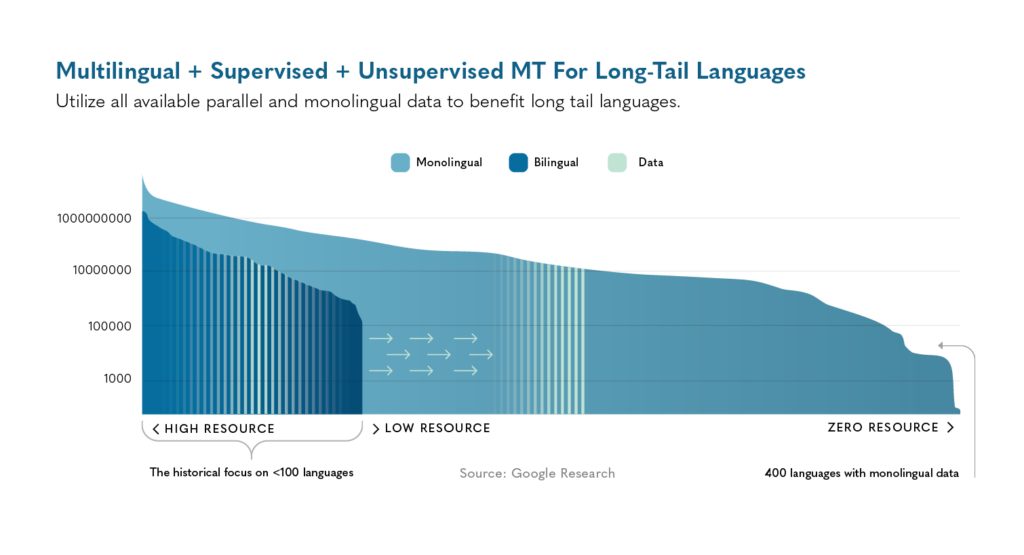
A Comprehensive Framework for Low-Resource Language Preservation
Drawing on insights from the LT4All 2025 conference and recent technological developments, it is possible to propose a four-phase framework for addressing the low-resource language dilemma.
Phase 1: Community Partnership and Community-Driven Data Curation
The initial phase must focus on establishing ethical partnerships with language communities and conducting comprehensive resource assessments. This process begins with identifying community leaders, language experts, and potential project champions who can guide the initiative.9 Rather than imposing external priorities, the assessment should document existing language resources (texts, recordings, dictionaries), digital infrastructure access, and community priorities for language preservation.
Taking lessons from the Masakhane community’s approach to African languages, projects should adopt inclusive authorship models that recognize diverse forms of contribution, including providing data and sharing lived experiences.10 The IndoNLP group’s approach to data ownership offers another important model, where control and ownership remain with original contributors rather than being appropriated by research institutions.11
The AI4Bharat initiative demonstrates how community engagement transforms data quality. For their 22-language IndicVoices corpus, linguists co-designed:
- Scenario-Based Collection: Simulated conversations about region-specific topics (e.g., Kashmiri shawl patterns) to capture domain-specific terminology.12
- Technological Accommodation: 8 kHz telephone recordings to include populations without smartphones.
- Demographic Stratification: Proportional representation across age groups, genders, and literacy levels.
This approach generated training data reflecting actual language use rather than idealized textbook forms. When adapted for judicial translation systems, these models reduced errors in Indian Supreme Court documents by 38% compared to previous tools.13
The All Lab’s work with African languages further illustrates this principle. By training models on folktales recorded by community elders rather than translated literature, their systems better preserve oral tradition structures and proverbial speech patterns.14
Phase 2: Targeted Data Collection and Infrastructure Development
Based on the community assessment, the second phase involves strategic collection focused on culturally significant and practically useful language content. This might include recording oral histories, documenting traditional knowledge, preserving ceremonial language, and capturing everyday conversations. The AmericasNLP approach of developing AI tools specifically to create educational materials for teaching indigenous languages provides an excellent model for aligning technological development with community needs.15
Technology capabilities within platforms that collect translation feedback could be valuable in this phase. New LLM-based translation capabilities that explain translation choices and seek clarification when encountering ambiguities make them well-suited for collaborative work with language experts.16
Technical infrastructure development during this phase should focus on creating accessible tools for community members to contribute to language documentation. This might include user-friendly mobile applications for recording and transcribing speech, web platforms for collaborative text creation and contribution, and quality assurance workflows that respect community expertise. The most successful outcomes will emerge from conducting participatory surveys and audits to inventory:
- Existing materials (oral histories, liturgical texts, folk songs).
- Digital literacy levels.
- Community priorities (education, media, governance).
The Masakhane Collective’s African language audits revealed that 72% of speakers prioritized children’s educational content over commercial applications, directing model development toward pedagogical tools.17
While crowdsourcing has been applied to low-resource language data collection, disconnects between data creation and model development processes can create challenges. A more comprehensive participatory approach addresses these limitations by involving language communities throughout the scientific process. This methodology aligns particularly well with low-resource scenarios where technical experts may lack essential cultural and linguistic knowledge, while community members may lack access to technical resources or training.
A key requirement during this phase is to develop technology that enables communities to:
- Record speech samples via mobile apps with built-in diarization.
- Transcribe texts using hybrid ASR/human validation workflows.
- Tag cultural metadata (e.g., ritual significance levels).
For the Māori language revival, developing the right tools increased usable training data by 140% annually through school participation programs.
In summary, based on collaboration between community leaders and AI technology expert assessments, this phase involves identifying the best way to enable strategic data collection:
1. Identify priority low-resource languages based on speaker population, endangerment level, and community interest.
2. Conduct a comprehensive inventory of existing linguistic resources, including parallel texts, monolingual corpora, and audio recordings.
3. Establish relationships with language communities, educational institutions, and cultural organizations.
4. Record oral histories, traditional knowledge, and everyday conversations using mobile applications.
5. Implement hybrid documentation workflows combining AI-powered transcription with human validation.
6. Tag cultural metadata to indicate ceremonial language, restricted knowledge, or contextual significance.
7. Create specialized collection protocols for domain-specific terminology (similar to AI4Bharat’s approach).
8. Form participatory research teams that include technical experts, linguists, and community members.
Phase 3: Monolingual Data Amplification: Technical Innovations
While community engagement provides the ethical foundation for language preservation efforts, innovative technical approaches enable more efficient use of limited language data. The LT4All 2025 conference highlighted several promising techniques for maximizing the value of monolingual data text or speech in a single language without translations or parallel corpora. Leveraging monolingual data through self-supervision emerges as a powerful technique for low-resource scenarios. Research presented by Google demonstrates that “using monolingual data significantly boosts the translation quality of low-resource languages in multilingual models”.18 This approach allows models to learn from text in a single language without requiring parallel translations, greatly expanding the pool of usable training data.
Back-translation represents one of the most successful approaches for low-resource MT.19 This technique involves translating monolingual target text into the source language to create synthetic parallel data, effectively augmenting the limited parallel corpora available. For significantly under resourced languages, iterative back-translation has proven valuable, whereby intermediate models of increasing quality are successively used to create synthetic parallel data for subsequent training iterations.
Self-supervised learning emerges as a particularly powerful approach for low-resource scenarios. Self supervised learning enables AI models to extract patterns from unlabeled monolingual data by predicting masked words or generating contextually appropriate text. Modern transformer-based architectures can identify linguistic patterns and develop foundational language representations even with relatively small amounts of text. This technique proves especially valuable for languages within the same language family, allowing knowledge transfer from well-resourced to under-resourced relatives.20
This approach has shown impressive results, with some implementations achieving “up to 28 BLEU on Romanian-English translation without any parallel data or back-translation.”21
Recent research presented at the 16th Conference of the Association for Machine Translation in the Americas demonstrated that fine-tuned MLLM models offer superior performance compared to their LLM counterparts when applied to crisis scenarios involving low-resource languages.22 This finding suggests that multilingual models with specific fine-tuning may provide more robust solutions than general-purpose LLMs for specialized domains. Transfer learning represents another critical innovation. By pre-training models on high-resource languages or multilingual datasets before fine-tuning on specific low-resource languages, researchers can leverage linguistic similarities and accelerate development.23 By leveraging knowledge gained from high-resource languages, researchers can initialize models that perform substantially better on low-resource pairs. This approach proves especially valuable for languages within the same language family, where grammatical structures and vocabulary may share common features, allowing knowledge transfer from well-resourced to under-resourced relatives.24
For languages with minimal bilingual corpora, recent advances enable unprecedented resource amplification. These include:
Self-Supervised Morphological Induction
Recent research initiatives have used transformer networks to infer grammatical rules from raw text. Analyzing Ukrainian’s agglutinative structure, the system deduced case endings and verb conjugations with 89% accuracy using only 50,000 monolingual sentences.25 This capability proves vital for polysynthetic languages like Inuktitut, where single words encode complex predicates.
Culturally-Grounded Model Training
Fine-tune base models using community-curated datasets, developing optional human validation for ceremonial language and traditional knowledge preservation.
This approach preserved Māori’s whakapapa (genealogical) speech patterns while filtering culturally sensitive terms.
Cross-Lingual Phoneme Mapping
The AmericasNLP initiative mapped Quechua’s ejective consonants to acoustically similar sounds in Spanish, enabling speech recognition development without parallel audio data. Emerging technology promises tonal language support using similar principles, transferring pitch pattern recognition from Mandarin to Vietnamese and Yorùbá.26
Synthetic Data Generation
Researchers suggest27 creating a pipeline to generate synthetic training pairs through:
- Back-Translation: Creating pseudo-parallel corpora from monolingual text.28
- Style Transfer: Rewriting sentences in different registers (formal ↔colloquial) to expand coverage.29
This approach expanded Nigerian Pidgin coverage from 10,000 to 450,000 phrases within six months.
Conversational Machine Translation Systems
The emerging “prompt-based conversational machine translation” (PCMT) system that combines traditional MT capabilities with LLM chatbots provides another avenue to collect relevant data.30 This interactive approach allows the system to express uncertainty, explain translation choices, request clarifications, and adapt based on user feedback. Such conversational interfaces are particularly valuable for low-resource scenarios where contextual understanding and iterative refinement can compensate for limited training data.
This combination of professional expertise and machine learning creates a system capable of handling nuanced translation tasks even with limited examples from specific language pairs.
Phase 4: Deployment, Continuous Improvement, and Cultural Integration
The final phase focuses on deploying developed technologies to serve community needs while establishing mechanisms for continuous improvement. Applications might include:
- Educational platforms that support language learning, particularly for younger generations.
- Documentation systems that preserve oral traditions and cultural knowledge.
- Translation tools that enable content consumption and creation in the native language.
- Communication technologies that facilitate intergenerational language transmission.
This phase focuses on community validation and establishing continuous improvement mechanisms:
1. Community linguist feedback loops where language experts review and correct model outputs.
2. Implementation of feedback and critique learning system which uses chain-of-thought reasoning and other algorithmic capabilities that benefit from human evaluations to refine the model.31
3. Development of community-specific applications based on priorities identified in Phase 1.
4. Establishment of sustainable governance structures for ongoing data collection and model updates.
Continuous Human-in-the-Loop Validation
The implementation of a Dynamic Feedback Protocol is a critical requirement:
1. Community linguists flag problematic outputs and provide continuous improvement feedback.
2. System traces decision pathways using attention visualization.
3. Retraining occurs regularly (daily or weekly) with new learning and constraints.
Application Areas and Expected Outcomes
Language preservation efforts should serve multiple generations within language communities, thus, LT4All’s “Three Generations” principle ensures tools serve:
For Elders and Knowledge Keepers
- Digital archiving of oral traditions and specialized knowledge.
- Speech recognition systems trained to understand dialectal variations and ceremonial speech.
- Documentation tools that preserve contextual knowledge alongside language.
For Adult Community Members
- Translation systems for civic documents, healthcare information, and educational materials.
- Content creation tools that support publishing in the native language.
- Professional development resources for language teachers and cultural workers.
For Youth and Future Generations
- Interactive language learning applications based on authentic cultural content.
- Social media tools that support native language communication.
- Creative platforms for developing contemporary cultural expression in traditional languages.
- The Cherokee Nation’s language app ecosystem increased teen proficiency from 12% to 34% in five years through TikTok-style challenges and AI-generated comics.
- Continuous improvement systems should incorporate feedback loops where community members can correct AI outputs, with these corrections feeding back into model refinement. This approach not only improves technical performance but also strengthens community engagement and ownership of the technology.

Imminent Science Spotlight
Academic lectures for language enthusiasts
Curated monthly by our team of forward-thinking researchers, the latest in academic insights on language and technology: a deep dive into ideas on the brink of change about large language models (LLM), machine translation (MT), text-to-speech, and more.
Dive deeperEthical Considerations and Sustainability
Throughout all phases, ethical considerations must remain paramount.
Data sovereignty principles, as modeled by the IndoNLP group, should ensure that language communities maintain control over how their linguistic data is used.32 Privacy protections must be robust, particularly when documenting sensitive cultural knowledge or personal narratives. These data use restrictions will be challenging to implement as AI technology does not understand language as such, and will require a major shift in data sovereignty perspectives within the technology community. Sustainability planning should address both technical and social dimensions. Technical sustainability includes knowledge transfer to community members, open-source development where appropriate, and infrastructure planning that accounts for local constraints. Social sustainability involves integrating language technologies into community institutions like schools, cultural centers, and governance structures.
Sustainability planning should address both technical and social dimensions:
1. Knowledge transfer to community members to reduce external dependencies.
2. Infrastructure planning that accounts for local connectivity challenges.
3. Integration with existing cultural institutions like schools and community centers.
4. Long-term funding models that maintain systems beyond initial development phases.
The Indigenized AI Manifesto (LT4All 2025)33 mandates:
- Custodianship: Communities retain data ownership.
- Restricted Access: Sensitive knowledge requires elder approval.
- Benefit Sharing: Commercial applications pay cultural royalties.
Conclusion: Toward Digital Linguistic Equity
The path forward for low-resource language preservation lies in thoughtfully combining community engagement with innovative AI technologies. Neither approach alone is sufficient-community involvement without technological leverage may struggle to overcome the scale of the challenge, while technical solutions without community partnership risk creating tools that fail to serve real needs or respect cultural contexts. The recent LT4All 2025 conference at UNESCO Headquarters affirmed that language technologies must advance humanism rather than merely advancing technology itself.34 By centering ethical partnerships with language communities and leveraging cutting-edge AI innovations like those embodied in Lara Translate, we can create a future where linguistic diversity thrives in the digital age. These efforts support not only communication but preserve the unique cultural wisdom, traditional knowledge, and distinct worldviews embedded in each language-enriching our collective human experience. By combining self-supervised learning with participatory design, we move closer to a world where technology doesn’t homogenize human expression but helps it flourish in glorious diversity.
As one participant at LT4ALL 2025 noted, “When a child can learn their ancestral tongue through an AI tutor crafted by their community, that’s when we’ll know the language singularity has truly been achieved.”
Read more



Kirti Vashee
Language technology evangelist at Translated
Kirti Vashee is a Language Technology Evangelist at Translated Srl, and was previously an Independent Consultant focusing on MT and Translation Technology. Kirti has been involved with MT for almost 20 years, starting with the pioneering use of Statistical MT in the early 2000s. He was formerly associated with several MT developers including Language Weaver, RWS/SDL, Systran, and Asia Online. He has long-term experience in the MT technology arena and prior to that worked for several software companies including, Lotus, Legato, & EMC. He is the moderator of the "Inner Circle" Automated Language Translation (MT) group with almost 11,000 members in LinkedIn, and also a former board member of AMTA (American Machine Translation Association). He is active on Twitter (@kvashee) and is the Editor and Chief Contributor to a respected blog that focuses on MT, AI and Translation Automation and Industry related issues.
References
1. Natural language processing applications for low-resource languages | Natural Language Processing | Cambridge Core.
2. Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries | Proceedings of the ACM Web Conference 2024.
3. Facebook translates ‘good morning’ into ‘attack them’, leading to arrest | Facebook | The Guardian.
4. AI moderation is no match for hate speech in Ethiopian languages. | Restoftheworld.
5. LT4All 2025 | UNESCO.
6. LT4All 2025 | ELRA.
7. Local AI Research Groups are Preserving Non-English Languages in the Digital Age | TechPolicy.Press.
8. Reviving Voices: How the African Languages Lab is Empowering Low-Resource 4. Long-term funding models that maintain systems beyond initial development phases.
The Indigenized AI Manifesto (LT4All 2025) mandates: Languages with AI. | SMARTLING.
9, 10, 11, 12, 13. Local AI Research Groups are Preserving Non-English Languages in the Digital Age | TechPolicy.Press.
14. AI in Language Preservation: Safeguarding Low-Resource and Indigenous Languages. | Welocalize.
15. Local AI Research Groups are Preserving Non-English Languages in the Digital Age | TechPolicy.Press.
16 Translated Introduces Lara | Translated.com.
17. Local AI Research Groups are Preserving Non-English Languages in the Digital Age | TechPolicy.Press.
18. Siddhant, A., Chaudhary, V., Firat, O., Tran, C., & Barham, P. (2020). Leveraging monolingual data with self-supervision for multilingual neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. | ACL Anthology.
19. Survey of Low-Resource Machine Translation | Computational Linguistics | MIT Press.
20. Chen, C.-C., Yılmaz, E., Gutierrez-Escolano, F., & Watanabe, S. (2023). Evaluating self-supervised speechrepresentations for Indigenous American languages. arXiv preprint arXiv:2310.03639. | arXiv.
21. Siddhant, A., Chaudhary, V., Firat, O., Tran, C., & Barham, P. (2020). Leveraging monolingual data with self-supervision for multilingual neural machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. | ACL Anthology.
22. Lankford, C., & Way, A. (2024). Leveraging LLMs for MT in crisis scenarios: A blueprint for low-resource languages. In Proceedings of the AMTA 2024 Conference. | ACL Anthology.
23. Zhong, T., Zhu, Y., Arkaitz, Z., Dandapat, S., & Yimam, S. M. (2024). Opportunities and challenges of large language models for low-resource languages in humanities research. arXiv preprint arXiv:2412.04497. | arXiv.
24. Chen, C.-C., Yılmaz, E., Gutierrez-Escolano, F., & Watanabe, S. (2023). Evaluating self-supervised speech representations for Indigenous American languages. arXiv preprint arXiv:2310.03639. | arXiv.
25. Kumar, S., Chaudhary, V., Sitaram, S., Bhat, G., Sun, H., & Black, A. W. (2022). Machine translation into low-resource language varieties. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. | ACL Anthology.
26. Translated Unveils Lara, A Breakthrough Translation AI System To Enhance Global Communication | GALA Global.
27. Survey of Low-Resource Machine Translation | Computational Linguistics | MIT Press.
28. Haddow, B., Bawden, R., Miceli Barone, A. V., Helcl, J., & Birch, A. (2022). Survey of low-resource machinetranslation. Computational Linguistics, 48(3), 673–732. | ACL Anthology.
29. Italian startup Translated launches Lara, an AI-powered translation tool to rival Google Translate, GPT-4o |Silicon Canals.
30. MT Tool Review: Lara by Translated | translated.com.
31. Italian startup Translated launches Lara, an AI-powered translation tool to rival Google Translate, GPT-4o | Silicon Canals.
32. Local AI Research Groups are Preserving Non-English Languages in the Digital Age | TechPolicy.Press.
33. Overview – LT4All 2025 | eu.com.
34. LT4All 2025 | UNESCO.